

The Productivity Paradox: When Fast Answers Create Slow Work
If you build with language models for a living, you learn a simple rule. A brilliant answer you cannot trust is a liability. Teams cheer for a vivid draft or a clean code snippet, then spend hours tracing a phantom citation through a document or a guessed function through a repo. The work looked fast. The review turned it into rework.
That is why GPT-5 reliability matters more than another point on a leaderboard. Reliability decides whether an AI system pays rent in production. This article lays out how GPT-5 shifts the center of gravity from flash to truth, why that shift unlocks real speed, and how to put those gains to work in your stack today. Along the way we will ground the story in the GPT-5 System Card, third-party results, and clear practices that reduce llm hallucinations where they do the most damage.
Table of Contents
1. The Real Bottleneck, When Pretty Answers Break Workflows
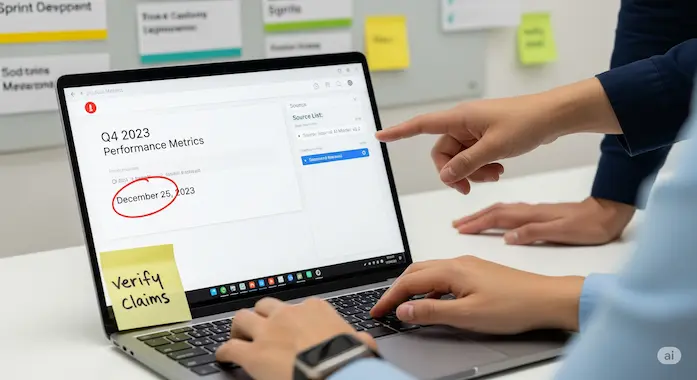
We have all seen the same pattern. You ask for a literature review, a migration plan, or a legal summary. The prose sings. The structure is tidy. Then a date is wrong, a case is invented, or an unfamiliar API call appears from thin air. Your stance flips from maker to chaperone. Time saved becomes time lost. These are not edge cases. They are the routine tax of llm hallucinations.
Three failure modes keep showing up:
- Hidden verification cost. Minutes saved on drafting vanish when people spend ten minutes checking every claim. A confident error produces work that looks complete, so it sneaks into slides, tickets, or PRs. That is the opposite of GPT-5 productivity.
- Trust erosion in high-stakes settings. One invented fact inside clinical, legal, or financial work is not a small miss. It is a critical failure. Without trust, teams keep models at arm’s length. GPT-5 reliability aims to change this posture.
- Fragile multi-step agents. A single hallucinated step, a missing file or a deprecated endpoint, collapses a chain. The dream of autonomous agents stalls. Cut those errors and you get real delegation. Again, the lever is GPT-5 reliability.
2. What Changed Under The Hood, The System Card as a Blueprint
The GPT-5 System Card reads like a research log. OpenAI did two important things. First, they built a grader that extracts factual claims from model outputs and checks them on the web. Humans cross-checked the grader and found strong agreement. Second, they tested at production scale in two modes. In browse on, the model can look things up. In browse off, it must rely on internal knowledge. That split matters. It tells you whether gains come from better search behavior, better world knowledge, or both.
This focus targets GPT-5 hallucinations at the source. If a model learns to show its work, cite sources, and abstain when a claim is thin, you lower error rates before the copyediting stage. That is the heart of GPT-5 reliability.
3. Factuality On Production Traffic
OpenAI’s own measurements include a head-to-head on real user traffic. The table below adapts results the GPT-5 System Card highlights, comparing new models to their predecessors on production prompts with browsing enabled.
Table 1: GPT-5 factuality vs previous models on production traffic
| Model Comparison | Metric | Previous Model | GPT-5 Model | Improvement |
|---|---|---|---|---|
| GPT-5 Thinking vs. OpenAI o3 | Hallucination Rate, percent incorrect claims | 12.7% | 4.5% | 65% reduction |
| GPT-5 Thinking vs. OpenAI o3 | Percent responses with 1+ major error | 22.0% | 4.8% | 78% reduction |
| GPT-5 Main vs. GPT-4o | Hallucination Rate, percent incorrect claims | 12.9% | 9.6% | 26% reduction |
| GPT-5 Main vs. GPT-4o | Percent responses with 1+ major error | 20.6% | 11.6% | 44% reduction |
These are not cosmetic wins. Fewer incorrect claims and fewer major errors mean fewer tense follow ups and fewer emergency edits. You feel it in calmer standups and cleaner reviews. This is GPT-5 reliability doing quiet, compound work. When people ask why GPT-5 productivity looks better, the answer begins here.
4. The Power Of “i don’t know,” Abstention as a Feature
Abstention is a skill. A disciplined no prevents cascades of bad work. The System Card reports that the thinking mini variant improves both accuracy and abstention on SimpleQA, dropping the hallucination rate far below earlier small models. A small model that refuses to bluff can be more useful than a larger model that guesses. This reduces GPT-5 hallucinations at the cheapest stage of a task, right when a wrong turn would branch into three more wrong turns. That safety net is now standard behavior, and it anchors GPT-5 reliability in daily use.
5. Why Reliability Equals Real Speed
If you measure speed honestly, you count review and rework. A model that writes fluent nonsense is not fast. A reliable model changes where time goes. Researchers spend more effort synthesizing ideas instead of hunting phantom citations. Engineers spend more effort on design instead of rubber-ducking code that never could have compiled. Writers invest energy in narrative and voice, not scavenger hunts for sources. Meetings shrink because people trust the first draft enough to start from it. That is the shape of GPT-5 productivity, and it flows directly from GPT-5 reliability.
6. AI Reliability Comparison, GPT-5 vs Claude 4.1 And Gemini 2.5 Pro
Direct apples-to-apples hallucination tests across vendors are still maturing, so many teams use difficult reasoning suites as a proxy for truthfulness. If a model performs at the top of graduate-level questions or legal reasoning, it is usually less prone to bluffing. The picture looks like this:
Third party results give external pressure tests. As of August 8, 2025, vals.ai shows a consistent picture across reasoning heavy suites. The scores below reflect both capability and discipline, models that chase points with guesses tend to bleed accuracy on these sets.
Table 2: AI Reliability Comparison on High-Stakes Benchmarks.
| Benchmark | Model | Accuracy | Rank | Cost In / Out | Latency |
|---|---|---|---|---|---|
| GPQA | Grok 4 | 88.1% | 1 | $3.00 / $15.00 | 115.52 s |
| GPQA | GPT-5 | 85.6% | 2 | $1.25 / $10.00 | 169.72 s |
| GPQA | GPT-5 Mini | 80.3% | 5 | $0.05 / $0.40 | 67.13 s |
| GPQA | Gemini 2.5 Pro Exp | 80.3% | 4 | $1.25 / $10.00 | 41.10 s |
| LegalBench | GPT-5 | 84.6% | 1 | $1.25 / $10.00 | 14.75 s |
| LegalBench | Gemini 2.5 Pro Exp | 83.6% | 2 | $1.25 / $10.00 | 3.51 s |
| LegalBench | Grok 4 | 83.4% | 3 | $3.00 / $15.00 | 24.22 s |
| MMLU Pro | Claude Opus 4.1, Nonthinking | 87.8% | 1 | $15.00 / $75.00 | 18.05 s |
| MMLU Pro | Claude Opus 4.1, Thinking | 87.6% | 2 | $15.00 / $75.00 | 27.67 s |
| MMLU Pro | GPT-5 | 87.0% | 3 | $1.25 / $10.00 | 32.52 s |
| MMMU | GPT-5 | 81.5% | 1 | $1.25 / $10.00 | 72.32 s |
| MMMU | Gemini 2.5 Pro Exp | 81.3% | 2 | $1.25 / $10.00 | 24.15 s |
| MMMU | o3 | 80.4% | 3 | $2.00 / $8.00 | 39.27 s |
| MMMU | GPT-5 Mini | 78.9% | 5 | $0.05 / $0.40 | 26.70 s |
A few practical reads:
- GPT-5 vs Claude 4.1. Claude Opus 4.1 edges GPT-5 on MMLU Pro with 87.8 to 87.0, which reflects strong breadth across academic domains. GPT-5 counters with first place on MMMU, a vision heavy suite that tends to punish shallow guessing.
- GPT-5 vs Gemini 2.5 Pro. On MMMU the gap is small, 81.5 for GPT-5 and 81.3 for Gemini 2.5 Pro Exp. On LegalBench GPT-5 leads with 84.6 to 83.6. On GPQA GPT-5 takes second behind Grok 4 while Gemini 2.5 Pro Exp sits a tier lower.
- Cost and latency. GPT-5’s input cost is materially lower than high end Claude tiers. GPT-5 Mini offers budget friendly accuracy on GPQA and MMMU with input at $0.05, which makes sense for background enrichment and tagging where you can tolerate a small drop in score.
None of these suites measure every skill. They do reveal a throughline. High performance on “Google proof” tests correlates with fewer invented facts. That is the heart of an AI reliability comparison.
7. How to Build For Reliability, Patterns That Hold up

You do not need a research lab to benefit from the System Card playbook. The patterns below turn GPT-5 reliability into a habit. They also reduce llm hallucinations without heavy process.
- Instrument claims and sources. Ask the assistant to extract bullet-point claims with links for every fact heavy answer. Store the claim list next to the output. This makes spot checks cheap and improves GPT-5 productivity by moving verification into a single pass.
- Count abstentions. Track how often the model declines to answer or asks for a pointer. Reward abstention when data is missing or the question is underspecified. You are training culture as much as a model. This reinforces GPT-5 reliability.
- Route by risk. Use faster modes for routine tasks, deeper reasoning for high risk work. Tell the assistant which mode is expected and why. This prevents overthinking on simple jobs and underthinking on critical ones.
- Validate formats. When downstream code expects JSON or a schema, ask for that format and validate it. A correct structure is a first line of defense against GPT-5 hallucinations.
- Constrain tools. Give agents a tight tool belt. File access, web domains, and API scopes should be explicit. The fewer degrees of freedom, the fewer ways to drift off course. This lock-in supports GPT-5 reliability during long runs.
- Sanitize inputs. Treat external text as data, not instructions. Strip or escape hostile prompts found in web pages or PDFs. This cuts prompt injection and stabilizes browsing, which in turn reduces hallucination cascades.
- Publish a tiny dashboard. Track claim count, source count, abstentions, and time to approval. Visualize drift. The moment the numbers move, review prompts and examples. Guardrails stay healthy when you watch them.
8. Risk, Ethics, And The Value Of A Careful “no”
Duty of care matters. When answers influence health, money, or safety, abstention is not failure. It is prudence. A model that says I do not know and asks for a check is a better partner than one that guesses with flair. The GPT-5 System Card treats measurement and disclosure as first class work. Do the same. Publish what you measure. Keep a changelog of failures and fixes. When people see a steady flow of small improvements, they believe that GPT-5 reliability is real. That trust is fragile. Keep earning it.
9. Operationalizing Reliability, The Boring Habits That Win
The winning posture looks boring, and that is the point.
- Define success per workflow. Name the claims that matter and the cost of getting them wrong.
- Put people in the loop where harm is possible. Remove toil where it is not.
- Require sources by default for fact heavy tasks.
- Store claims and sources with the output so reviews are fast.
- Rotate third-party tests to avoid overfitting.
- Share postmortems with clear fixes, not blame.
Do this, and GPT-5 reliability compounds into quiet on-call shifts, quicker approvals, and cleaner audits. Your backlog moves because work stops bouncing between teams. Your meetings shrink because people trust the first pass. Your incident reviews get shorter because the assistant made fewer unforced errors. That is practical GPT-5 productivity.
10. A Short Buyer’s Guide, Pick Models By Rework, Not By Vibe
There is a simple way to choose across vendors. Build a weeklong AI reliability comparison that counts rework. Pick ten tasks that look like your real backlog. Require claim lists and citations. Log abstentions. Time each draft to approval. Score the work, then repeat with a new set of tasks the next week. Publish the results internally. The model that wins is the one that wastes the least time. Over and over, teams find that GPT-5 reliability pulls ahead when you include the hidden costs. That does not mean GPT-5 wins every lane. It means you will see where it wins for your jobs, and why.
For completeness, here is how to read the head-to-heads:
- GPT-5 vs Claude 4.1. If your tasks prize tone and friendly coaching, Claude is a great pick. If your tasks prize sourcing discipline under pressure, GPT-5 reliability often feels stronger.
- GPT-5 vs Gemini 2.5 Pro. If you want fast vision and mixed media on light risk jobs, Gemini is fast and capable. If your pipeline leans on careful browsing, source control, and long, referenced drafts, GPT-5 reliability tends to reduce edits and retries.
11. Where The Gains Will Show Up Next
Capability will keep rising. The next breakthroughs will make browsing smarter, tool use safer, and abstention more nuanced. That last part matters. A crisp no is already valuable. A graded no, with a short uncertainty note and a shopping list of what would change the answer, is even better. As those behaviors improve, GPT-5 reliability will feel less like a feature and more like table stakes.
Two areas will deliver outsized returns:
- Source selection. Teaching models to prefer stable, first-party sources cuts error rates on its own. When the assistant knows the difference between a press release and a peer-reviewed paper, GPT-5 hallucinations drop again.
- Tool verification. Simple pre-checks, such as listing files before using them and dry-running database writes, stop full runs from failing late. This multiplies the value of GPT-5 reliability in agent workflows.
12. Putting It All Together, Reliability As The Quiet Competitive Edge
The story is not that GPT-5 can write better jokes or longer code. The story is that it wastes less of your attention. Words match the world more often. When they do not, the model says so and asks for a check. The result is fewer fire drills and more real progress. GPT-5 reliability pulls effort out of policing and funnels it into building. That flow is where the leverage lives.
If you remember one theme, remember this. Reliability is speed in disguise. When you reduce llm hallucinations, you cut rework, which cuts cycle time, which frees heads for higher order problems. That is the flywheel behind GPT-5 productivity. It begins with careful engineering, visible in the GPT-5 System Card, and it continues with small team habits that keep answers honest.
Make those habits normal. Instrument claims. Reward abstention. Constrain tools. Sanitize inputs. Validate outputs. Measure what you care about. Share what you learn. Do these boring things, and you will feel GPT-5 reliability in your calendar, your pull requests, and your error budget. It is not a slogan. It is the quiet edge that lets the rest of your roadmap actually land.
Closing Thoughts, The Calm After The Hype
The AI race started with flash. Then it learned to listen. Now it is learning to tell the truth more often, and to admit uncertainty when truth is not on tap. That pivot is the main event. When answers are grounded and checkable, attention returns to real work. Meetings get shorter. On-call grows quiet. The product gets better because the team finally has the time to make it better. That is the promise behind GPT-5 reliability, and it is the reason the conversation is shifting from launch parties to dashboards.
Signal beats noise. Process beats pitch. Reliability beats vibe. If you want leverage this quarter, start with GPT-5 reliability. Build the habits that reward it. Measure the parts that matter. Run your own AI reliability comparison so your team believes the story. The rest is compounding interest. The hype fades. The work remains. With GPT-5 reliability, the work finally moves.
Azmat — Founder of Binary Verse AI | Tech Explorer and Observer of the Machine Mind Revolution.
Looking for the smartest AI models ranked by real benchmarks? Explore our AI IQ Test 2025 results to see how today’s top models stack up. Stay updated with our Weekly AI News Roundup, where we break down the latest breakthroughs, product launches, and controversies. Don’t miss our in-depth Grok 4 Review, a critical look at xAI’s most ambitious model to date.
For questions or feedback, feel free to contact us or browse more insights on BinaryVerseAI.com.
Why is it a big deal that GPT-5 can say “I don’t know”?
A careful no prevents costly errors. When GPT-5 abstains, it signals uncertainty, requests permission to browse, or hands off to a human. That behavior avoids false facts in high-stakes tasks, improves auditability, and builds user trust. Calibrated answers are the backbone of gpt-5 reliability.
How does reducing hallucinations actually increase productivity?
Reliability cuts rework. Less time goes into line-by-line fact checks, cleanup of wrong citations, and debugging code that never could have compiled. Teams move from policing to building. Approvals arrive faster, agent workflows fail less, and context switches drop. In practice, fewer gpt-5 hallucinations translate into real gpt-5 productivity.
How does GPT-5’s reliability compare to other top AI models like Claude 4.1 and Gemini 2.5 Pro?
Each model has strengths. Claude 4.1 often shines on instruction following and friendly tone. Gemini 2.5 Pro is strong on speed and multimodal tasks. GPT-5 emphasizes calibrated answers, browsing quality, and abstention, which many teams experience as fewer corrections in reference-heavy work. The best way to decide is an AI reliability comparison on your own tasks, with claim lists, sources, and time-to-approval measured across models.
What are LLM hallucinations?
LLM hallucinations are confident answers that are not grounded in facts or sources. They show up as invented citations, non-existent APIs, misattributed quotes, or wrong numbers that look plausible. Causes include ambiguous prompts, weak grounding, distribution shifts between training data and the real world, and pressure to complete a pattern instead of verifying a claim. Reducing llm hallucinations is central to gpt-5 reliability.
Does GPT-5 still hallucinate?
Yes, any large model can still be wrong. The difference is rate and recovery. According to the GPT-5 System Card and third-party evaluations, GPT-5 shows a lower frequency of gpt-5 hallucinations in both browse-on and browse-off tests, and it backs off more often when uncertain. That combination improves gpt-5 reliability without sacrificing fluency.
How did OpenAI reduce hallucinations in GPT-5?
OpenAI focused on truthfulness as an engineering target, not an afterthought. Key levers include:
Claim-level grading with a browser-enabled evaluator that flags incorrect statements for training and testing.
Better abstention behavior, so GPT-5 says I do not know instead of guessing.
Stronger browsing discipline that prefers high quality sources and summarizes rather than copies.
Safer tool use, with checks before file operations or API calls.
Training data curation and evaluation suites that punish unsupported claims.
These choices, documented in the GPT-5 System Card, compound into higher gpt-5 reliability.