

You’ve seen the clips. A robot sorts clutter, packs a suitcase, and even recovers when something goes wrong. Half the internet says, this is insane. The other half asks, haven’t we watched slick robotics demos for a decade? Here’s the difference this time. With Gemini Robotics, Google DeepMind pulled two hard problems into one working stack, thinking before acting, and sharing skills across different robot bodies. That shift, quiet and technical, is why this release matters.
This piece cuts through the spectacle. We’ll unpack what Gemini Robotics is, how the 1.5 update changes the game, and where it actually stands today. We’ll focus on two ideas that anchor the announcement, embodied reasoning and motion transfer AI, then answer the practical questions about cost, reliability, and the future of robotics. Along the way, we’ll translate the tech report into plain English and actionable takeaways for builders and teams.
Table of Contents
1. What Is Gemini Robotics, From A Model To An Agentic System

Gemini Robotics isn’t a single neural net. It is an agentic system with two specialized models that operate like brain and body. The high level planner, Gemini Robotics-ER 1.5, handles embodied reasoning, tool use, and multi step plans. The action model, Gemini Robotics 1.5, is a vision-language-action model that turns instructions and pixels into motor commands and short, reliable motion segments. Together, they let a Google DeepMind robot perceive, decide, and then execute.
This architecture does something simple that robotics desperately needed. It splits long horizon, abstract decisions from low level control, then lets the action model “think” in short internal steps before it moves. That separation improves reliability and makes behavior easier to understand and audit.
1.1 The Two Model Stack, At A Glance
| Layer | Formal Name | Role In The System | Typical Inputs | Typical Outputs | Core Strengths |
|---|---|---|---|---|---|
| Orchestrator | Gemini Robotics-ER 1.5 | Plans the mission, reasons about space, calls tools when needed | Instructions, scene cues, external tools | Stepwise natural language plans for each subtask | Embodied reasoning, spatial understanding, tool use, safety-aware planning |
| Action Model | Gemini Robotics 1.5 | Executes each step with precise motion, thinks before acting | RGB frames, text step, proprioception | Short segments of motor commands and corrective substeps | Vision-language-action control, internal monologue for multi step tasks |
Sources, tech report descriptions of roles, thinking, and planning.
2. The First Breakthrough, Embodied Reasoning, The Thinking Robot
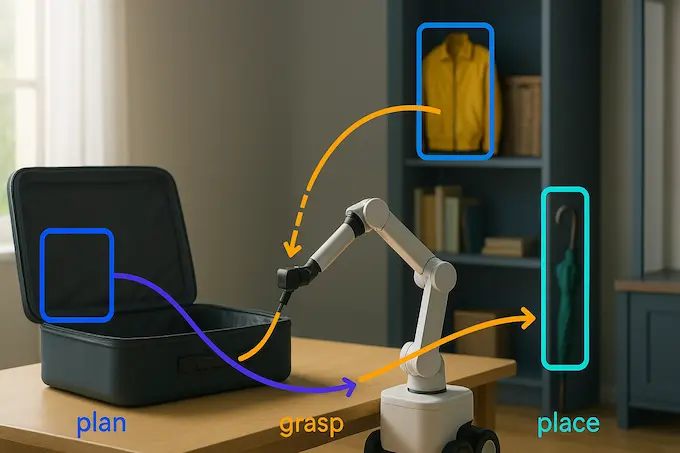
Embodied reasoning is the point where an AI stops being a clever autocomplete and starts being a reliable field teammate. It means the system builds a mental sketch of the room, the objects, and the constraints, then breaks a vague request into a chain of concrete steps.
Ask it to pack for a rainy London trip, and the orchestrator checks weather and itinerary, proposes a plan, and hands short natural language steps to the action model. The action model then decomposes each step into bite sized motions, for example, move left gripper to jacket, close gripper, lift, place in bag. That inner monologue makes the robot’s behavior more transparent and more robust.
In the tech report this shows up as “thinking helps acting.” The model performs better on multi step tasks when it writes out its reasoning and translates it into short motion segments it can actually execute. That sounds obvious. It is also exactly what most prior vision-language-action systems were missing.
3. The Second Breakthrough, Motion Transfer, One Shared Mind Across Many Bodies

Robots come in wildly different forms. A table mounted ALOHA arm, a bi arm Franka setup, a full humanoid like Apollo. Traditionally, each one needs a separate policy trained on its own demo data. Gemini Robotics 1.5 attacks that bottleneck with motion transfer AI. The training recipe and architecture align different embodiments so the model learns a unified sense of motion and contact. Skills learned on one platform become usable on another, often zero shot.
3.1 A Quick Look At The Multi Embodiment Fleet
Training spans ALOHA, bi arm Franka, and the Apptronik Apollo humanoid, with thousands of diverse tasks across scenes. The breadth matters. It forces the vision-language-action model, the VLA, to learn regularities that survive changes in body plan, camera placement, and reach.
3.2 Why Motion Transfer Changes The Curve
If you’ve spent time in robotics, you know the drill. New robot, new dataset, same months of effort. With the Gemini Robotics motion transfer recipe in place, data from one embodiment flows to the others. The ablation plots show that adding cross embodiment data helps, and the motion transfer training amplifies that help by aligning embodiments in the representation. That is how you turn expensive bespoke datasets into compounding assets.
4. How Far Along Is It, A Practical Reality Check
Let’s address the skepticism head on. Is this just another polished montage, or are we seeing consistent gains under real evaluation? The report is unusually disciplined on this front.
4.1 Is This Just Another Faked Demo
No. The team runs A/B and A/B/n tests on real robots, interleaving models on the same work cell to reduce variance. They also scale development with a physics simulator, MuJoCo, and measure rank consistency between simulation and real success. That lets them try many ideas before they burn physical time, while still keeping real hardware as the final judge. Over 90 percent of development evaluation episodes ran in simulation, and the sim to real rank ordering held across tasks. That is what you want to see if you care about reproducibility.
4.2 What Do Long Horizon Tasks Look Like
Not every task is pick and place. The paper includes long horizon evaluations on ALOHA and Franka that require planning, tool use, recovery, and successful completion, not just making partial progress. You see success rates, not only progress scores, and the full agent, Gemini Robotics-ER 1.5 plus Gemini Robotics 1.5, outperforms a stack that swaps in a weaker planner. The message is clear. Planning quality upstream shows up as measurable wins downstream.
4.3 The Failure Modes That Actually Got Better
Here is where the work gets specific. The authors catalog common ways robots fail on household tasks, then compare two agents. One uses Gemini 2.5 Flash as the planner. The other uses Gemini Robotics-ER 1.5. The GR-ER agent reduces failure patterns like confusing tools, skipping substeps, and brittle execution under small changes. That detail is the difference between sorting props on a lab bench and placing the right dish in the right cupboard at home.
4.4 What About Cost And Economics
It’s fair to say hardware is pricey today. That said, the software approach in Gemini Robotics is built to scale. One checkpoint controls very different bodies out of the box. That is the kind of reuse that pulls per unit costs down as deployments grow, especially across Multi embodiment control that look nothing alike. Multi embodiment control, plus motion transfer AI, is exactly how you escape one robot, one dataset economics.
4.5 Will This Replace Human Jobs
Short answer, some tasks, yes. Full jobs, slower. The immediate impact lands where workflows break into many repeatable steps with clear visuals and clear success checks. Think back rooms, micro fulfillment, and certain station based tasks in light manufacturing. The same ingredients, embodied reasoning and a strong VLA, also open valuable augmentation patterns.
A Google DeepMind robot that can plan, ask for missing context, and adapt mid task will pair well with humans who manage ambiguity, tidy goals, and handle exceptions. The future of robotics is not single task arms on industrial lines. It’s systems that can generalize, learn quickly from a handful of examples, and take feedback in natural language.
5. What Builders Can Do Right Now
- Separate orchestration from control. Let a planner write the step list in natural language. Let a VLA turn the step list into motion segments, complete with internal reasoning. This improves debuggability because plans are readable. It also improves robustness because thinking precedes action.
- Adopt progress scores. Success is binary. Progress isn’t. Use graded progress definitions for evaluation, then report success rates alongside them for the big picture. Your team will iterate faster because you can see which parts of a long task fail first.
- Exploit motion transfer. When you add a new body, don’t start your data budget from zero. Align embodiments in the representation. Train with cross embodiment data. You’ll see better generalization and better data efficiency, especially when two robots share subskills like latching, pulling, or drawer manipulation.
- Use simulation with discipline. A good simulator pays for itself if you calibrate it and track rank consistency against real robots. That combination is how you test more ideas without grinding hardware.
5.1 Table, Where The Agentic Split Pays Off
| Scenario | Planner Output | Action Model Behavior | Why It Works |
|---|---|---|---|
| Packing for a trip | A readable plan, pack jacket, check weather, select items, verify bag state | Short internal steps, reach, grasp, place, with corrections | The planner stays abstract. The VLA handles geometry and timing with thinking before acting |
| Desk tidy | List of zones and targets, cables, mugs, papers | Segmented motions with progress checks between zones | Clear boundaries let the VLA recover if something slips or blocks the path |
| Drawer tasks | Step language, open drawer, fetch item, close drawer | Composed push, pull, and grasp motions | Composing learned subskills beats monolithic policies |
Source, agentic pipeline and thinking segments in the report.
5.2 Table, Common Failure Modes And The Fix
| Failure Mode In Household Tasks | What Went Wrong In Weaker Agents | What Improved With GR-ER 1.5 As Planner |
|---|---|---|
| Tool confusion | Picks wrong implement or wrong drawer | Better grounding in task context and spatial cues |
| Skipped substep | Leaves lid on, never checks bin label | Planner enumerates required substeps, action model executes them in sequence |
| Brittle sequence | Small scene change collapses the plan | More resilient step lists and recoverable motion segments |
Source, comparison of failure patterns across agents.
6. Why This Feels Like A Turning Point
The novelty isn’t that a robot can put a cup on a shelf. We’ve had that for years. The novelty is that Gemini Robotics makes the cup, the shelf, and the instruction live inside one consistent story, from plan to motion, across very different bodies. The VLA thinks before it moves. The planner reasons about space, uses tools, and speaks in steps the controller can execute. Motion transfer AI lets lessons from one robot show up on another. This is how you turn a set of demos into an approach.
A few details worth calling out from the tech report:
- One checkpoint, many bodies. Gemini Robotics 1.5 controls three very different robots out of the box, without per body specialization after training. That is a big cost lever for any team that manages multiple platforms.
- Cross embodiment transfer is measured, not implied. The paper defines explicit benchmarks where the model solves tasks only seen on other robots. Zero shot transfer is the bar.
- Simulation is used with guardrails. The team shows rank consistency between MuJoCo and real robots, then leans on simulation for more than 90 percent of development episodes. That balance speeds iteration without disconnecting from reality.
7. A Clear View Of What Comes Next
Let’s keep our heads. General purpose robots won’t sweep every category overnight. Battery density, hand design, and actuation still gate what you can do in the field. That said, the path forward is now clearer than it has been in years. If you can plan in language, act with a vision-language-action model, and move skills across bodies, you can start shipping useful systems sooner. The stack in Gemini Robotics is a blueprint for exactly that. It is how a Google DeepMind robot can step beyond a staged demo and into a day job.
If your team is exploring this space, sketch a narrow pilot. Pick a workflow with visual clarity, frequent repetition, and a small handful of tools. Collect demonstrations on one robot, then validate on another. Use progress scores to find weak links, then close the gap with better plans and more precise motion segments. That is the sober way to turn research into value.
7.1 The Thesis In One Line
Gemini Robotics 1.5 is a milestone because it tackles two blockers at once, brittle planning and fragmented robot skills. Embodied reasoning fixes the first. Motion transfer fixes the second. Together they nudge general purpose robots closer to everyday use.
8. Closing, Build Something Useful, Then Share What Worked
If you’re a researcher, publish your progress score recipes and your cross embodiment results so others can reproduce them. If you’re an engineer, stand up a two model agent, planner plus VLA, then measure how much thinking helps acting on your tasks. If you lead a product group, pilot something boring and valuable, not just camera ready. Laundry folding is a meme. Stockroom picks, kitting, and daily desk reset are markets.
This is your call to action. Treat Gemini Robotics like a set of patterns you can use, not a press clip to admire. Then, when your Google DeepMind robot quietly cleans a lab, closes a drawer, and recovers from a mistake without fuss, you’ll know why the hype finally lined up with reality.
Key sources from the official tech report are cited inline.
1.1 What Is Gemini Robotics 1.5, And How Is It Different From Previous Models?
Gemini Robotics 1.5 is a vision-language-action model that turns images and instructions into robot motor commands, and it “thinks before acting” to improve reliability. It works with Gemini Robotics-ER 1.5, the planner that reasons about space and calls tools like Search. The dual-model stack enables longer, multi-step tasks and cross-robot generalization.
1.2 What Is “Embodied Reasoning” And Why Is It A Breakthrough For Robots?
Embodied reasoning is a robot’s ability to understand a physical scene, plan step by step, and evaluate progress. Gemini Robotics-ER 1.5 performs this role, including tool use and spatial reasoning, then hands executable steps to the action model. The result is clearer plans, better error recovery, and more transparent decisions in natural language.
1.3 What Is “Motion Transfer” And How Does It Help Different Robots Learn Faster?
Motion transfer lets skills learned on one robot apply to others with different bodies. In Gemini Robotics 1.5, tasks trained on platforms like ALOHA or Franka can run on a humanoid such as Apollo without retraining from scratch. This tackles data scarcity and speeds deployment across mixed fleets.
1.4 Is This Just Another Impressive Demo, Or Can These Robots Perform Real-World Tasks?
The release pairs real hardware evaluations with reproducible setups and shows multi-step tasks such as sorting, tidying, and packing that hinge on planning plus execution. Independent coverage corroborates the shift from single commands to problem solving guided by web tools and internal reasoning.
1.5 Will Gemini Robotics And Other General-Purpose Robots Replace Human Jobs?
Expect task-level automation first. The stack is built to handle repeatable steps in logistics, manufacturing, and service workflows, while humans manage ambiguous goals and exceptions. Broader job impact depends on economics, safety, and policy. Today, ER 1.5 is available to developers and the action model is limited to partners, which moderates near-term displacement.