

Speed vs Quality vs Cost (Bubble = Output Price)
X: output speed, Y: GPQA Diamond, bubble size: $/1M output tokens
Tip: the sweet spot is top-right with a smaller bubble.
Google dropped Gemini 3.1 Flash-Lite on March 3, 2026, with essentially no advance notice. One day it wasn’t there, the next it was sitting quietly in AI Studio and Vertex AI under a preview tag, daring developers to benchmark it.
If you’ve followed the Reddit conversation since, you’ve seen two reactions collide: impressed engineers noting the benchmark gains and annoyed developers doing the math on what the new pricing actually means. This Gemini 3.1 Flash-Lite review aims to be both honest about what changed and genuinely useful about when it makes sense for your stack. If you’re evaluating where this fits alongside other frontier models, our LLM pricing comparison and best LLM for coding 2025 guides are worth a read before diving in.
Let’s get into it.
Table of Contents
1. The Gemini 3.1 Flash-Lite Drop: What You Need to Know
Gemini 3.1 Flash-Lite is Google’s fastest and most cost-efficient model in the Gemini 3 series. It’s built for high-volume developer workloads and latency-sensitive pipelines: think translation queues, classification layers, audio transcription, and document triage. The model supports multimodal inputs (text, image, video, audio, PDF) with a 1M token context window and produces up to 64K output tokens per call.
According to Artificial Analysis benchmarks, it delivers 363 tokens per second output speed, a 2.5x faster time to first answer token compared to Gemini 2.5 Flash, and a 45% increase in overall output throughput. It scores 86.9% on GPQA Diamond, 76.8% on MMMU-Pro, and lands at 1432 Elo on the Arena.ai leaderboard. Those are not “lite” numbers.
Here’s how it stacks up against the field at a glance:
| Benchmark | Gemini 3.1 Flash-Lite | Gemini 2.5 Flash | Gemini 2.5 Flash-Lite | GPT-5 Mini | Claude 4.5 Haiku |
|---|---|---|---|---|---|
| Input Price ($/1M tokens) | $0.25 | $0.30 | $0.10 | $0.25 | $1.00 |
| Output Price ($/1M tokens) | $1.50 | $2.50 | $0.40 | $2.00 | $5.00 |
| Output Speed (tokens/s) | 363 | 249 | 366 | 71 | 108 |
| GPQA Diamond | 86.9% | 82.8% | 66.7% | 82.3% | 73.0% |
| MMMU-Pro | 76.8% | 66.7% | 51.0% | 74.1% | 58.0% |
| Video-MMMU | 84.8% | 79.2% | 60.7% | 82.5% | N/A |
| MMMLU (Multilingual) | 88.9% | 86.6% | 84.5% | 84.9% | 83.0% |
| LiveCodeBench | 72.0% | 62.6% | 34.3% | 80.4% | 53.2% |
| SimpleQA Verified | 43.3% | 28.1% | 11.5% | 9.5% | 5.5% |
The model is based on Gemini 3 Pro architecture, trained on Google’s TPU Pods using JAX and ML Pathways. It’s available via the Gemini API, Google AI Studio, and Vertex AI, with the model code gemini-3.1-flash-lite-preview.
2. The Pricing Controversy: Why Did the “Lite” Cost Go Up?
Here’s where the Reddit threads got loud, and honestly, the frustration is fair.
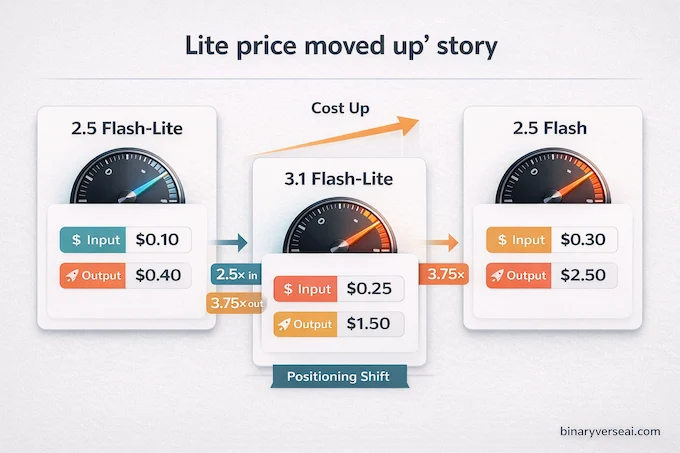
The Gemini 3.1 Flash-Lite price sits at $0.25 per million input tokens and $1.50 per million output tokens. Compare that to Gemini 2.5 Flash-Lite, which ran at $0.10 input and $0.40 output. That’s a 2.5x increase on inputs and a 3.75x increase on outputs. For a model with “Lite” in the name, that’s a meaningful jump. For a broader view of how these numbers compare across the market, see our LLM cost calculator.
Google’s marketing framing leaned on the comparison to Gemini 2.5 Flash ($0.30 input, $2.50 output), which makes 3.1 Flash-Lite look like a bargain. And against that specific baseline, it is. But developers who were using 2.5 Flash-Lite as their cheap workhorse for classification, translation, or routing are looking at a substantially higher bill for similar workloads.
Is the intelligence bump worth it? That depends entirely on what you’re doing. If you’re running tens of millions of tokens per day on simple text-only tasks, the cost increase is material and hard to justify. If you’re doing anything multimodal, anything requiring genuine reasoning, or anything where answer quality directly affects user experience, the performance gap between 2.5 Flash-Lite and 3.1 Flash-Lite is significant enough to make the new pricing defensible.
The honest summary: Google moved the “Lite” tier upmarket. This is a strategic repositioning, not just a model refresh.
3. Speed and Benchmarks: Gemini 3.1 Flash-Lite vs. The Competition
Speed is the headline feature, and the numbers hold up. At 363 tokens per second, Gemini 3.1 Flash-Lite vs. 2.5 Flash isn’t even close. The older model managed 249 tokens per second. For real-time voice pipelines, live chat agents, or any application where latency is a first-class constraint, that gap matters enormously. For additional context on how Flash-Lite fares on math-specific evaluations, our Gemini math benchmarks breakdown is worth checking.
On reasoning benchmarks, the model genuinely surprises. An 86.9% score on GPQA Diamond, a test built to stump PhD-level scientific reasoning, is remarkable for a model at this price point. For context, Gemini 2.5 Flash scores 82.8% and Claude 4.5 Haiku comes in at 73.0%. On MMMU-Pro, measuring multimodal understanding, 3.1 Flash-Lite scores 76.8% against 2.5 Flash-Lite’s 51.0%. That’s not a marginal upgrade, that’s a fundamentally more capable model.
Video-MMMU performance at 84.8% also stands out. If you’re building anything that processes video content (lecture recordings, product demos, customer service calls), Gemini 3.1 Flash-Lite has a clear advantage over most similarly priced alternatives.
One area where the model underperforms is factual recall (SimpleQA Verified at 43.3%) and the FACTS Benchmark Suite (40.6% vs. Gemini 2.5 Flash’s 50.4%). For use cases where precise factual accuracy is critical, you’ll want to ground outputs with retrieval or search. That’s not a flaw unique to this model, it’s a calibration reminder.
4. The Open-Source Threat: Does It Beat Qwen and MiniMax?
Several developers on r/singularity dismissed the release immediately. The argument went: “Qwen 3.5 on Groq is faster and cheaper. This is DOA.”
That framing misses what Gemini 3.1 Flash-Lite is actually selling. Open-source models running on Groq are excellent for text-in, text-out tasks with modest context windows. But they can’t natively handle a 500-page PDF, an hour-long audio file, and a spreadsheet in a single API call. Gemini 3.1 Flash-Lite can, and it does so against a 1M token context window with consistent latency. Our Qwen3 Coder review and MiniMax M2 review cover those open-source alternatives in depth if you want a direct comparison.
The multimodal capability isn’t a checkbox feature here. It removes an entire infrastructure layer. You don’t need a separate speech-to-text pipeline, a separate PDF parser, or a separate image captioning service. You send the raw file and get structured output back. For teams building fast, that simplicity is worth real money.
Open-source is the right call for high-volume, text-only workloads where you can manage your own inference infrastructure. Gemini 3.1 Flash-Lite earns its place when your inputs are messy, multimodal, and massive.
5. The Killer Feature: Adjustable “Thinking Levels” in the API
This is the most underreported part of the release, and for developers it’s the most important.
Gemini 3.1 Flash-Lite ships with configurable thinking levels via the Gemini API. You can pass a thinking_level parameter, currently supporting “low”, “medium”, and “high”, to control how much internal reasoning the model performs before producing its final output. In Google’s terminology this is part of the Gemini Deep Think API surface, giving you explicit control over the tradeoff between latency, cost, and answer quality in a single model.
The code is as clean as it sounds:
response = client.models.generate_content(
model="gemini-3.1-flash-lite-preview",
contents="How does AI work?",
config=types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(thinking_level="high")
),
)This is a genuinely useful design. Previously, you’d choose between a fast cheap model for simple tasks and a slow expensive model for complex ones. Now you can use the same model, tune the reasoning depth per request, and manage cost dynamically. For agentic pipelines where task complexity varies wildly across users and sessions, this is a meaningful capability upgrade.
Here’s a practical thinking level guide by use case:
| Use Case | Thinking Level | Why It Works |
|---|---|---|
| High-volume translation | Low (default) | Speed and cost matter most |
| Content moderation | Low / Medium | Fast classification at scale |
| Model routing classifier | Low | Single-turn decision, 1-3 steps |
| Structured JSON extraction | Medium | Schema adherence without expensive reasoning |
| UI / dashboard generation | High | Complex multi-step instruction following |
| Audio transcription | Low | Parallelizable, no reasoning required |
| PDF document triage | Medium | Summarization quality improves with extra compute |
| Simulation generation | High | Creative, ambiguous tasks need full thinking budget |
The Gemini API thinking level configuration is currently available in preview and works in both AI Studio and Vertex AI.
6. Practical Use Case 1: High-Volume Intelligent Model Routing
One of the smartest patterns in production LLM systems is the idea of a routing layer: a cheap, fast model that reads each incoming request and decides whether to handle it directly or escalate to a more capable and expensive model. Gemini 3.1 Flash-Lite is purpose-built for this role. If you’re building agentic systems on top of this pattern, our guide to agentic AI tools and frameworks covers the broader orchestration landscape.
The open-source Gemini CLI already does this in production, using Flash-Lite to classify task complexity and routing to Flash or Pro accordingly. The setup is straightforward. You give the model a structured system prompt that defines what counts as simple versus complex, ask it to return a JSON object with a model_choice field, and route the request based on the output.
CLASSIFIER_SYSTEM_PROMPT = """
You are a Task Routing AI. Classify the user's request.
Return JSON with 'reasoning' and 'model_choice' (flash or pro).
COMPLEX tasks: 4+ steps, strategic planning, deep debugging, high ambiguity.
SIMPLE tasks: highly specific, bounded, 1-3 tool calls.
"""
response = client.models.generate_content(
model="gemini-3.1-flash-lite-preview",
contents=user_input,
config={
"system_instruction": CLASSIFIER_SYSTEM_PROMPT,
"response_mime_type": "application/json",
"response_json_schema": response_schema
},
)At 363 tokens per second, the routing decision adds negligible latency. The cost of the classifier call is a rounding error compared to what you save by not sending every request to Pro. This is one of those patterns that feels clever the first time and obvious the second.
7. Practical Use Case 2: Audio Transcription and Data Extraction
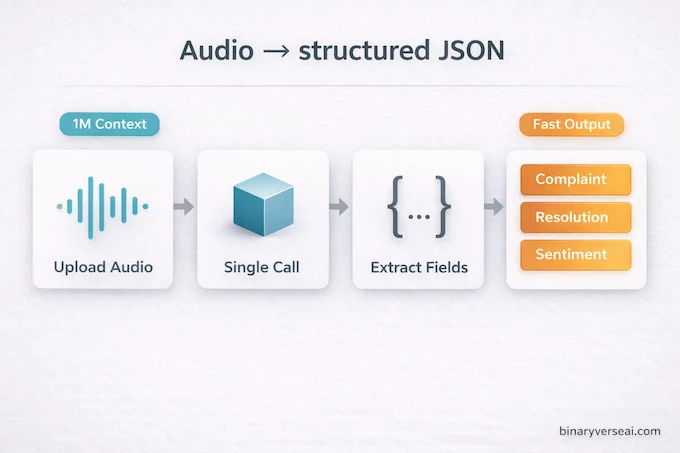
The transcription use case quietly solves a real infrastructure headache. Traditional audio-to-text pipelines involve a dedicated speech recognition service, format conversion, chunk management for long files, and then a separate LLM call for anything beyond raw text output. Gemini 3.1 Flash-Lite collapses that into a single API call. For teams building voice-first products, also see how the Gemini Live API fits into real-time audio architectures.
uploaded_file = client.files.upload(file='customer_call.mp3')
response = client.models.generate_content(
model="gemini-3.1-flash-lite-preview",
contents=["Extract the customer complaint, resolution, and sentiment as JSON.", uploaded_file]
)You get structured output back directly from raw audio. No pipeline orchestration, no intermediate storage, no format mismatch. For teams processing customer service calls, earnings call recordings, or voice note archives, this is the kind of simplification that makes real workflow differences.
The 1M context window means you can pass in long recordings without chunking. The 363 token per second output speed means results come back fast enough to power near-real-time analytics dashboards.
8. Content Safety and the Hallucination Rate
The model card data on safety is worth reading carefully, particularly for enterprise teams. Google’s official model card details the full evaluation methodology if you want to go deeper.
Gemini 3.1 Flash-Lite shows a 14% reduction in unjustified refusals compared to Gemini 2.5 Flash-Lite. That means borderline prompts that previously triggered unhelpful deflections are now handled more appropriately. The model’s refusal tone also improved by roughly 14.6%, meaning when it does decline a request, the response is better calibrated and less jarring for end users.
On image-to-text safety evaluations, the model showed a notable regression of 21.7% compared to 2.5 Flash-Lite. Google’s own review confirmed these losses were overwhelmingly either false positives or non-egregious, and red teaming found no critical issues. Still, teams building products with user-generated image inputs should budget time for safety testing specific to their content domain.
For child safety specifically, Gemini 3.1 Flash-Lite satisfied Google’s required launch thresholds, and red teaming found no egregious concerns across content safety policies generally.
On hallucinations and factuality, the SimpleQA Verified score of 43.3% and FACTS Benchmark of 40.6% are honest reminders that this model was not designed as a factual oracle. Use retrieval grounding (the API supports Search Grounding directly) for anything where factual accuracy is a hard requirement. Our Gemini RAG stacks guide covers how to set this up properly.
9. The Verdict: Is Gemini 3.1 Flash-Lite the Right Model for You?
Here’s the honest breakdown.
Skip it if you’re running high-volume, text-only workloads and your primary constraint is cost. At 3.75x the output price of 2.5 Flash-Lite, open-weight models self-hosted or running on Groq will beat it on economics for pure text tasks. The intelligence gains don’t justify the increase if your inputs are simple and your outputs are short.
Use it if you’re building anything that involves real-time responses, multimodal inputs, or large-scale data extraction from messy sources. The combination of 363 tokens per second, a 1M multimodal context window, and adjustable thinking levels gives you a genuinely flexible foundation for production systems that would otherwise require multiple specialized services working in coordination. For those evaluating the full Gemini 3 family across enterprise deployments, our Google Gemini enterprise pricing and features guide is a useful companion.
This is the model for enterprise voice agents that need low latency and audio understanding. Multimodal dashboards ingesting PDFs, images, and video. Agentic pipelines where task complexity varies and you need dynamic cost control. Any system where the simplicity of a single API call replacing three specialized services has real architectural and operational value.
The Gemini 3.1 Flash-Lite price is higher than its predecessor, and that’s a legitimate concern for cost-sensitive workloads. But Google didn’t just speed up an existing model. They shipped a thinking-capable, multimodal, production-grade system at a price point that genuinely undercuts Claude 4.5 Haiku by 4x on output tokens. Google’s official announcement and the launch post on X from GoogleDeepMind have additional context on the release strategy.
If your architecture is constrained by what a “lite” model used to mean, it’s worth revisiting those assumptions. Gemini 3.1 Flash-Lite has moved the tier.
Ready to test it? Gemini 3.1 Flash-Lite is live in preview at Google AI Studio with free API access during the preview period. Start with the model routing pattern, it pays for itself within the first few thousand requests.
1) Why is Gemini 3.1 Flash-Lite more expensive than 2.5 Flash-Lite?
Gemini 3.1 Flash-Lite costs $0.25 per 1M input tokens and $1.50 per 1M output tokens, about 2.5× to 3.75× higher than 2.5 Flash-Lite. Google positions it closer to 2.5 Flash in speed and quality, so the “Lite” label now means “lighter than Flash,” not “cheapest tier.”
2) Is Gemini 3.1 Flash-Lite better than open-source models like MiniMax M2.5 or Qwen?
For short, text-only generation, open-source models on fast inference stacks can be cheaper. Gemini 3.1 Flash-Lite wins when you need 1M-token context plus native multimodal inputs like PDFs, audio, and video, especially for enterprise extraction and routing workflows.
3) What is the “Thinking Level” in the Gemini API?
The Gemini API thinking level lets you control how much internal reasoning the model does before answering. You can keep it low for high-volume tasks like translation, or raise it for harder work like structured extraction, tool orchestration, and code reasoning, trading cost and latency for better accuracy.
4) How fast is Gemini 3.1 Flash-Lite in real use?
Gemini 3.1 Flash-Lite is designed for very low latency and high throughput, with output around 363 tokens per second in published comparisons. It’s built for real-time experiences like voice agents, moderation, and high-frequency app workflows where response speed matters as much as quality.
5) What happened to Gemini 3.0 Flash-Lite?
Google’s naming moved quickly. Instead of a widely marketed “3.0 Lite,” the lineup jumped to Gemini 3.1 Flash-Lite to align with the Gemini 3.1 family upgrades, especially the new reasoning controls like Thinking Levels and the broader “3.1” positioning.