

Scaling Laws for Neural Language Models: A Guide to Emergent AI Behavior
Scaling laws for neural language models have become the compass guiding the evolution of large language models (LLMs)—charting how model performance scales with compute, data, and parameters. Initially defined by the Kaplan scaling laws, and later refined by Chinchilla scaling laws, these empirical patterns promise smooth, predictable improvements. Yet beneath that elegant curve lies something stranger: emergence.
This article unpacks how neural scaling laws explain not only steady gains but also surprising skills in large language models that seem to appear out of nowhere. From chain-of-thought reasoning to complex code synthesis, examples of emergent behavior in GPT models defy gradual expectations and resemble phase shifts, not progress bars.
It also asks deeper questions: Does AI understand or merely simulate reasoning? And what happens when LLM scaling laws fuel capabilities faster than alignment protocols can catch up? With policy now tethered to empirical checkpoints and Chinchilla-style token efficiency, the article warns that future gains could require regulatory brakes.
Ultimately, the trajectory set by scaling laws for neural language models suggests we may see models with lab assistant autonomy, multi-agent collaboration, and self-healing code. But just as important as forecasting gains is remembering the blind spots—where power laws track performance averages but miss seismic leaps in intelligence.
In short, this long-form piece reveals how AI scaling laws illuminate the path forward—and why the map is never the territory when the terrain is emergent behavior.
1. Introduction – When Curves Start to Whisper
The first time I plotted validation loss against compute on a log log chart, the line looked almost too perfect—an elegant slope hinting that bigger truly is better. Then, right at the tail end, my model solved a multi step reasoning task it had always fumbled. I hadn’t changed the code, the optimizer, or the data pipeline; I’d merely nudged the parameter count past a trillion. That quiet jolt of capability is why I’ve spent the last two years obsessed with scaling laws for neural language models.
Today, the conversation around scaling laws for neural language models is no longer academic. The laws guide investment decisions, architecture choices, even government policy. Yet the very same graphs that promise smooth, predictable gains also conceal sharp cliffs of emergent behavior—moments when a model abruptly performs feats that smaller cousins cannot even parse. My goal in this long read is to unpack that tension: how scaling laws for neural language models both forecast and fail to forecast the future of large language models (LLMs), why those failures matter, and how we can ride the wave without wiping out.
By the end, you’ll understand not just the curves but the quirks—why a 70 billion parameter network can beat a 540 billion parameter one, how a tweak in token budget can outshine another doubling of FLOPs, and why surprise is baked into the mathematics. Most of all, you’ll see that predictability and unpredictability are two sides of a single coin minted by scaling laws for neural language models.
Table of Contents
2. A Quick Primer on Scaling Laws for Neural Language Models
Before we tackle emergence, we need a shared map of the territory. Scaling laws for neural language models are empirical relationships that link three levers—model size, dataset size, and training compute—to a single outcome: loss (or accuracy). Roughly speaking:
- Kaplan scaling laws (2020) revealed a clean power law: double any of the three levers while holding the other two constant and you squeeze loss by a predictable factor.
- Chinchilla scaling laws (Hoffmann et al., 2022) refined the recipe, arguing that the compute budget is best spent on more tokens, not more parameters. Their Chinchilla model (70 B parameters, 1.4 T tokens) beat much larger GPT 3 variants by respecting this balance.
- Neural scaling laws appear to hold across seven orders of magnitude—meaning the same straight line describes everything from a 10 M parameter toy to a trillion scale behemoth.
Why does any of this matter? Because scaling laws for neural language models let us forecast returns on hardware spend, estimate carbon cost, and even set research agendas. If the curve says another order of magnitude will shave 0.05 bits per byte off loss, venture capital and policy makers listen.
But here’s the punchline: every so often the neat power law bends, a new capability appears, and our precious forecast looks like yesterday’s weather map. That bend is where emergence lives.
3. The Math Behind the Magic—And Its Blind Spots
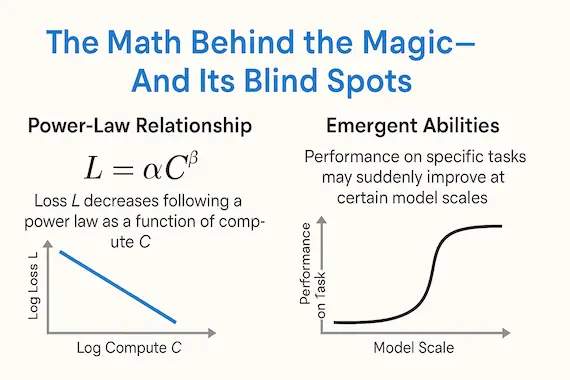
When you plot loss LL against effective compute CC on a log log scale, scaling laws for neural language models give you
L=αC−β ,L = \alpha C^{-\beta};,
where α and β are constants determined empirically. It’s a seductive equation: straight lines, no surprises. Yet two caveats lurk beneath the elegance.
- Power laws describe averages, not individual skills. The same model can improve steadily on next token prediction while failing catastrophically at long division—until one day it doesn’t.
- Sigmoid substructure. Recent meta analyses (Ruan et al., 2024) show many micro tasks follow S curves hidden inside the headline power law. The sigmoid’s steep middle section is where emergence explodes.
Put differently, scaling laws for neural language models are thermometers, not seismographs—they track temperature but miss earthquakes.
To illustrate, imagine tracking exact match accuracy on multi digit arithmetic. For seven model checkpoints you record zeros. On checkpoint eight, accuracy jumps to 98 %. Did the temperature change? Yes, but the thermometer told you only the average. The earthquake happened between samples.
4. Emergent Behavior: When the Thermometer Shatters
4.1 What Makes a Capability “Emergent”?
Jason Wei’s canonical definition is crisp: A skill is emergent if it is absent in smaller models yet present in larger ones. Under scaling laws for neural language models, you’d expect gradual improvements—but emergence looks like a step function.
Typical emergent talents include:
- Chain of thought reasoning: useless in GPT 2, game changing in GPT 4.
- Tool use and code synthesis: nonexistent at 6 B parameters, robust at 175 B.
- Long horizon planning: marginal in early transformers, surprising strong in models beyond the 1 T parameter mark.
4.2 Why Emergence Happens
Two forces conspire:
- Capacity thresholds. A network needs enough neurons to represent multi step dependencies; below that threshold, it simply can’t encode the requisite patterns.
- Data diversity. Even if the net has room, it must see enough varied examples for gradient descent to sculpt the right circuits. Chinchilla style token flooding shows that when you feed a model 4× more data without enlarging it, you can trigger emergence earlier.
Hence scaling laws for neural language models act like a fuse: lengthen the fuse (more parameters), pour gunpowder (more tokens), and the talent ignites.
4.3 Metric Illusions
Stanford HAI warns that some supposed jumps are artifacts of binary metrics. Measure arithmetic via exact match, and you’ll record zeros until the model nails every digit; switch to log likelihood, and you’ll notice steady improvements. So part of our astonishment stems from what we choose to measure. Still, not all bends are illusions—nobody disputes the moment GPT 4 began writing fully functional React apps from scratch.
5. 2024–2025: New Papers, New Curves, New Surprises

Scaling laws for neural language models kept morphing over the last eighteen months. A few highlights:
- MiniCPM upended the iconic 20 tokens per parameter ratio, advocating 192 tokens per parameter. Their smaller models learned faster than giants trained under classic budgets.
- LLaMA 3 & 4 pushed the ratio above 1 875 tokens per parameter, arguing that mainstream LLMs remain under sampled.
- Mixture of Experts (MoE) architectures introduced conditional computation. An MoE obeys its own family of llm scaling laws, where the number of active experts becomes the new knob. The implication? You can dial capacity without incurring full compute cost—a cheat code for the scaling game.
- Vision language models (Gemini 2.5 Pro, Claude 3.7 Vision) demonstrated that ai scaling laws hold across modalities, albeit with different exponents.
Across these studies, one pattern recurs: whenever a lab re balances size and tokens according to fresh empirical curves, emergence shows up earlier and cheaper. In other words, the better we tune scaling laws for neural language models, the sooner we hit the weird stuff.
6. Do Big Nets Understand or Merely Imitate?
I once asked a friend to translate a poem into French by feeling each stanza before typing. GPT 4 produced a rival translation in seconds. Does that mean GPT 4 understood the poem? Experts would say it mapped the poem into a high dimensional semantic space; understanding, in the human sense, lives elsewhere.
This controversy predates deep learning—Searle’s Chinese Room is older than I am—but scaling laws for neural language models throw fresh fuel on the fire. When a billion parameter net hallucinates nonsense, we shrug: small nets are dumb. When a trillion parameter net drafts a passable legal contract, we wonder: is it thinking or stitching?
My pragmatic take is borrowed from Hinton: intelligence is not one thing but a bundle of affordances. If the bundle expands every time scaling laws for neural language models crank up, metaphysics may matter less than safety. Speaking of which…
7. Safety, Alignment, and Policy on a Moving Train
Alignment is hard when the target keeps accelerating. Scaling laws for neural language models guarantee that tomorrow’s frontier model will wield abilities absent today. Anthropic’s Responsible Scaling Policy formalizes that reality: evaluation gates tighten as loss plunges and emergent scores spike.
Three principles guide the emerging consensus:
- Pre deployment red teaming escalates with scale. Bigger model, harsher gauntlet.
- External audits—SOC 2, ISO 27001, NIST—become table stakes once a model crosses thresholds derived from chinchilla scaling laws or kaplan scaling laws curves.
- Kill switches by design. The capacity for tool use must ship with scoped permissions and human override.
Policymakers now draft regulation that ties permissible deployment to empirical checkpoints in scaling laws for neural language models. When your graph says the next training run will double effective reasoning depth, you might need a license, a risk report, or both.
8. Looking Ahead—Beyond the Next Power Curve
Where do scaling laws for neural language models point? If current exponents hold, a 10× jump in compute by 2027 should cut loss another 40 %. By then, we may see:
- Autonomous lab scientists that propose, test, and refine hypotheses overnight.
- Multi agent swarms coordinating via internal language to solve open research problems.
- Self debugging codebases where the compiler is half LLM, half static analyzer.
Yet nothing in the equations guarantees alignment will improve as fast. The same curves that gift us startling skills also widen the cliff edge. Geoffrey Hinton’s warning—that humanity might be a passing phase in the evolution of intelligence—echoes louder each time I retrain a model.
Scaling laws for neural language models therefore demand both reverence and skepticism: reverence because they unlock predictive power unmatched in AI history; skepticism because they whisper half truths, hiding the jumpy, jagged nature of real capability growth.
Further Reading
If you’d like to wander deeper down the rabbit hole, explore these seminal works and recent updates:
- J. Kaplan et al., Scaling Laws for Neural Language Models (2020)
- J. Hoffmann et al., Training Compute Optimal Large Language Models (Chinchilla, 2022)
- J. Wei et al., Emergent Abilities of Large Language Models (2022)
- Y. Ruan et al., Observational Scaling Reveals Sigmoid Substructure in LLM Performance (2024)
- Meta AI, LLaMA 3 Technical Report (2024)
Author’s Note
I wrote the first draft of this essay during a storm in Lahore, while fine tuning a toy transformer that still confuses Urdu and Punjabi. The irony wasn’t lost on me: my GPU hummed through rolling blackouts, chasing curves that promise tomorrow’s models will out reason me. Perhaps they will. Until then, scaling laws for neural language models remain both my compass and my caution sign—and I wouldn’t have it any other way.
- Emergent Abilities of Large Language Models – Wei et al., 2022
- Scaling Laws for Neural Language Models – Kaplan et al., 2020
- Emergent Abilities in LLMs: An Explainer – Center for Security and Emerging Technology
- Training Compute-Optimal Large Language Models – Chinchilla, DeepMind 2022
- Chinese Room Argument – Stanford Encyclopedia of Philosophy
- OpenAI’s Preparedness & Safety Framework
- Show Glossary
- Scaling Laws for Neural Language Models: Empirical rules that predict how performance improves with size, data, and compute.
- Neural Scaling Laws: Broader term covering scaling patterns across various neural networks beyond language models.
- LLM Scaling Laws: Scaling laws specific to large language models, often tracking text prediction accuracy vs. resources.
- Emergent Behavior: A capability that appears abruptly in models after reaching certain thresholds of scale.
- Chinchilla Scaling Laws: Emphasize more data per parameter for optimal performance; improves efficiency over Kaplan’s model.
- Kaplan Scaling Laws: Original scaling law framework showing a power law relationship between compute, size, and loss.
- Power Law: Mathematical relationship where one variable grows as a power of another—used in scaling law formulations.
- Sigmoid Substructure: Concept suggesting skill emergence follows S-shaped curves beneath smooth average performance graphs.
- Mixture of Experts (MoE): Network architecture activating subsets of the model per input, enhancing scale efficiency.
- Exact Match vs. Log-Likelihood Metrics: Metrics comparison where exact match exaggerates emergence, while log-likelihood shows gradual improvement.