

Introduction
If you’ve watched AI “solve” math lately, you’ve probably felt the same whiplash I have. One day it’s confidently inventing a theorem. The next day it’s quietly nailing a proof that would have made your younger self sweat through three notebooks.
The interesting part is not that models got better at talking about math. It’s that we’re starting to see systems that behave more like a lab partner than a chatbot. They try an idea, get called out by a critic, patch the hole, and only then hand you something that resembles a proof you can work with.
That’s the vibe behind Aletheia DeepMind. It’s not a magical AGI oracle. It’s a carefully engineered research workflow built around Gemini Deep Think, plus a verification loop and real tool use, aimed at one thing: pushing reliable reasoning further than one-shot “let me think” prompts can.
Now to the headline that made everyone look up from their terminals: 91.9% on IMO-ProofBench Advanced, with a gap so large it doesn’t look like a normal leaderboard anymore. Let’s unpack what that means, why it happened, what it actually solved, and what you can try today if you want the closest practical version of this idea.
Table of Contents
1. Aletheia DeepMind In One Paragraph: What It Is, What It Is Not
Aletheia DeepMind is best understood as an Aletheia math research agent, not a single chat model. It wraps an advanced reasoning model (Gemini Deep Think) inside a loop that repeatedly generates, verifies, and revises candidate solutions in natural language, and it leans on tools like web search to avoid the most common research-grade failure mode: plausible-sounding nonsense with fake citations.
What it is not: a push-button theorem machine that guarantees novelty, formal rigor, or publication-ready proofs on demand. It’s more like a high-end “proof intern” with a very fast scratchpad and a stern internal reviewer.
Here’s the quickest orientation I can offer before we get technical:
| Quick Orientation | The Useful Mental Model |
|---|---|
| What it is | A workflow that runs generate verify revise loops until a solution passes a verifier or the system admits defeat |
| What it is not | A single chat response you should trust without checking |
| What it optimizes | Fewer hidden gaps, fewer hallucinated citations, better long-horizon consistency |
| What it still can’t promise | Novelty, perfect rigor, formal proof correctness, or “major breakthroughs” on command |
If you remember only one line, make it this: Aletheia DeepMind is a reliability upgrade achieved by process, not just by raw model IQ.
2. Aletheia DeepMind And The 91.9% Breakaway Moment On IMO-ProofBench Advanced
Benchmarks rarely feel like “events.” They’re usually a slow grind of small gains and debates about prompt format. This one felt different because the gap is cartoonish.
IMO-ProofBench Advanced lives under the broader IMO-Bench effort, designed to stress multi-step reasoning and proof quality in a way that looks closer to how mathematicians grade, not how multiple-choice tests grade.
Here’s the leaderboard snapshot you provided (query date noted in your table):
| Model | Advanced ProofBench | Novel | IMO 2024 | USAMO 2025 | Query Date |
|---|---|---|---|---|---|
| Aletheia | 91.9% | 92.1% | 100.0% | 83.3% | 2026-02-09 |
| GPT-5.2 Thinking (high) | 35.7% | 26.2% | 66.7% | 50.0% | 2026-01-14 |
| Gemini 3 Pro | 30.0% | 31.0% | 23.8% | 40.5% | 2026-01-14 |
| GPT-5 Pro | 28.6% | 29.4% | 19.0% | 35.7% | 2025-11-26 |
| Claude Opus 4.5 | 23.8% | 21.4% | 14.3% | 42.9% | 2026-01-14 |
| Grok 4.1 Fast Reasoning | 18.6% | 19.8% | 16.7% | 16.7% | 2025-11-26 |
| GPT-5.1 | 7.1% | 1.6% | 14.3% | 16.7% | 2025-11-26 |
Read that again: 91.9% versus 35.7% for the next entry. That’s not “slightly better.” That’s “you’re measuring a different thing.”
Which brings us to the first honest question smart people asked.
3. Agent Vs Model Fairness: Is This An Apples-To-Oranges Leaderboard?
Yes and no.
Yes, because Aletheia DeepMind is not “just a model.” It’s an agentic system with orchestration, retries, internal critique, and often tools. If you compare it to a raw model run once with no scaffolding, you’re grading a bicycle against a commuter train.
No, because the point of a research agent is the workflow. In real math and science, nobody gets one shot. Humans draft, check, refute themselves, try again, look things up, and sometimes walk away. A benchmark that punishes systems for doing the thing researchers actually do is the unfair benchmark.
So the clean answer is this:
- If your question is “Which base model is smarter per token,” then a system-level score is not the comparison you want.
- If your question is “Which approach produces the most correct proofs under realistic constraints,” then Aletheia DeepMind is exactly the kind of system you should be measuring.
This is why “Agent vs model fairness” is not a philosophical side quest. It’s the whole lesson.
4. Architecture Overview: Generator To Verifier To Reviser
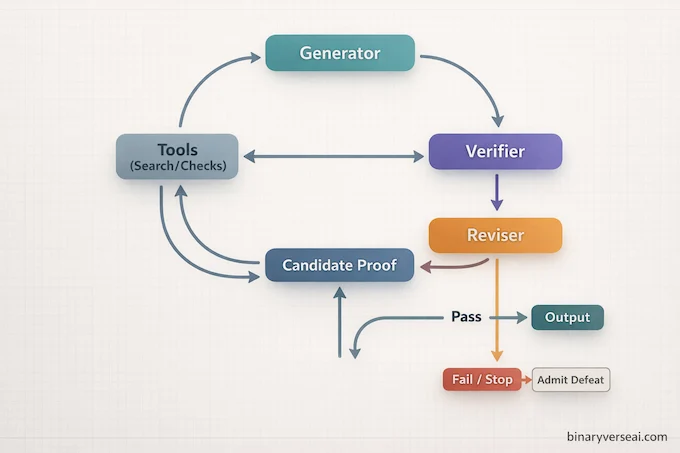
At the heart of Aletheia DeepMind is a loop that sounds simple and behaves like a cheat code once you’ve built one yourself:
Generator → Verifier → Reviser, repeat.
This is the generator verifier reviser pattern, or in the simpler phrasing I like, generate verify revise.
4.1 The Generator: Fast, Messy, Creative
The Generator’s job is breadth. It produces candidate solution paths, proof sketches, lemmas, and sometimes multiple competing approaches. It’s allowed to be wrong early, because the next component exists to be judgmental.
4.2 The Natural Language Verifier: The Internal Skeptic
The natural language verifier is the vibe shift. Instead of trusting the same stream of thought that created the proof, the system explicitly asks, “Where are the gaps?” This separation matters because it breaks the model out of its own momentum.
DeepMind’s framing is direct: decouple generation from verification, and you often catch flaws the model happily stepped over a minute earlier.
4.3 The Reviser: Targeted Repairs, Not A Full Restart
The Reviser takes the Verifier’s critique and patches. Sometimes it rewrites a step. Sometimes it replaces a lemma. Sometimes it admits the approach is doomed and tells the Generator to try a different route.
The underrated feature here is the ability to admit failure. Research time is precious, and a system that can say “I’m stuck” is more useful than one that confidently hands you garbage.
5. How Verification Works: What The Natural Language Verifier Checks, And What It Can’t

Let’s get concrete about what “verification” means here, because it’s easy to hear that word and imagine formal proof checking. This isn’t that.
The natural language verifier checks things that humans check when reading an informal proof:
- Did you use the hypothesis you claim you used?
- Did you silently assume something false, like a quantity being positive or an inequality direction?
- Did you swap “for all” and “there exists” without noticing?
- Did you reference a theorem that doesn’t apply to this setting?
This targets the most common failure mode in LLM math: a proof that feels smooth until you stare at line 7 and realize it teleported.
What it cannot guarantee:
- It cannot guarantee novelty.
- It cannot guarantee full rigor in the formal sense.
- It cannot guarantee you didn’t “prove” something by smuggling in the conclusion.
That’s why the papers around this work keep emphasizing human expert grading and collaboration. The verifier raises the floor. It doesn’t replace mathematicians.
6. Research Hygiene: Literature Search, Grounding, And The Subconscious Plagiarism Anxiety
Once you move beyond contest math, the real enemy is not algebra. It’s the library.
Research-level problems sit on top of decades of results. A model with a big training set still struggles with two ugly realities:
- It can hallucinate citations.
- It can accidentally reinvent something that already exists, then present it as new.
DeepMind’s approach leans heavily on tool use, especially search and browsing, because it reduces blatant fake references and shifts the error profile toward subtler mistakes, like citing a real paper for a claim the paper does not contain.
The Erdős case study paper calls out an even more human-sounding fear: “subconscious plagiarism.” The idea is not that the system is malicious, it’s that when you’ve seen enough math text, you can reproduce patterns without correctly attributing where they came from, or even remembering you saw them. That risk becomes central when you run an AI across hundreds of “open” problems at scale.
If you want a practical takeaway, it’s this: the more “researchy” the task, the more the workflow needs explicit steps for grounding and attribution, not just reasoning.
7. What Counts As Solving An Open Problem: The Erdős Sweep, Erdős-1051, And What “Open” Means
The most click-worthy claim in this whole story is the Erdős angle, so let’s treat it with adult-level precision.
The semi-autonomous case study reports a systematic pass over 700 conjectures labeled “Open” in Bloom’s Erdős problems database, using a hybrid method: AI-driven verification to narrow candidates, then human expert evaluation to judge correctness and novelty.
The punchline is quietly deflating in a useful way. The paper reports that many “Open” labels were open due to obscurity, not because the problems were world-historic barricades. It also reports that out of the set they focused on, some “open” problems were already solved in the literature, they were just not marked that way in the database.
This is where Erdős-1051 comes in. The Aletheia paper describes an autonomous solution and a push toward a generalization that led to follow-on work.
So what does “solved” mean here?
- Sometimes it means: “We found a correct argument that resolves the stated question.”
- Sometimes it means: “We found that the question was already answered, then surfaced the reference.”
- Sometimes it means: “We contributed an intermediate proposition that strengthened a human proof.”
That spectrum is not a weakness. It’s the honest shape of research support.
And it’s why you should keep this anchor question in mind when reading hype: What counts as solving an open problem?
8. Beyond Erdős: What The Two DeepMind Papers Actually Claim
If you only read the benchmark tweets, you miss the more interesting story, the collaboration patterns.
One paper, Towards Autonomous Mathematics Research, frames Aletheia DeepMind as a research agent built on Gemini Deep Think, inference-time scaling, and tool use, and it proposes a taxonomy for levels of autonomy and novelty so the public doesn’t confuse “cool milestone” with “landmark breakthrough.”
The other, Accelerating Scientific Research with Gemini: Case Studies and Common Techniques, zooms out to math, CS theory, economics, optimization, and physics, and it emphasizes the methods that worked: iterative refinement, decomposition, cross-domain transfer, adversarial review, and in some cases code-driven checking loops.
That combination matters. It suggests the core innovation is not a single trick. It’s a repeatable recipe for human-AI collaboration that looks like serious work, not demo theater.
9. Why The Performance Jump Happened Now: Inference-Time Scaling Meets Workflow Engineering
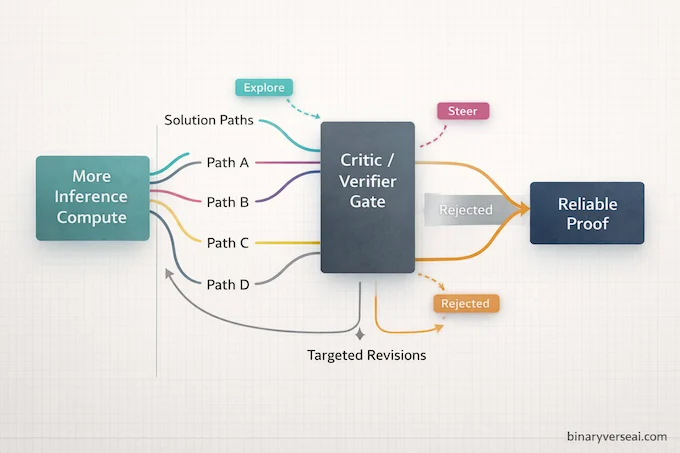
It’s tempting to explain everything with “bigger model,” but the papers keep pointing to a different lever: more compute at inference time, spent exploring more solution paths, plus a better harness that can exploit that exploration without drowning in its own output.
This is the part that feels very engineering-coded.
If you scale inference compute naively, you get a larger pile of thoughts, including more wrong ones. If you scale inference compute inside a generate verify revise loop, you get something closer to beam search with a critic, and the system can spend its extra budget turning “almost right” into “actually right.”
In other words, the jump is not just horsepower. It’s steering.
10. Is Aletheia Publicly Available: Cost, Access, And How To Try The Closest Thing Today
Let’s answer the question people really mean when they ask “how to use Gemini Deep Think.”
10.1 How To Use Gemini Deep Think
In the Gemini app experience, Google’s own help docs describe using Deep Think as a toggle in the prompt UI: open Gemini, type your prompt, tap Deep Think, then submit.
That gives you the model mode. It does not automatically give you the full agent harness that makes Aletheia DeepMind special.
10.2 Gemini Deep Think API And Gemini API Pricing
For developers, Google publishes Gemini Developer API pricing in its official docs, with per-token rates that vary by model and tier, plus separate pricing for features like context caching and grounding with Google Search.
If your goal is “Deep Think API,” read that page carefully, then treat cost as a function of two knobs you control: how much context you feed, and how much thinking you let it do.
10.3 The Reality Check
As described in the research framing, Aletheia DeepMind is an internal research agent workflow, not a simple public product button you can click and get 91.9% out of the box.
The closest thing you can do today is build your own mini version:
- Generate 3 to 10 candidate solutions.
- Run a separate verifier prompt that aggressively hunts gaps.
- Revise only what was flagged.
- Stop early when the verifier can’t find holes, or stop when you hit a budget cap.
That loop is the transferable idea.
11. Gemini Deep Think Vs Deep Research: The One-Minute Clarification
People keep mixing these up because both feel like “stronger mode.”
A useful way to separate them:
- Gemini Deep Think is primarily about deeper reasoning and longer deliberation, often with parallel exploration.
- Deep Research is primarily about research-style workflows that gather, organize, and synthesize information, often with more explicit browsing and multi-step reporting.
They overlap. They are not the same tool. If you want proof-level reliability, you care more about the verifier loop than the label on the button.
12. What This Does, And Doesn’t, Imply About AGI
If you’ve read the comment threads, you’ve seen the AGI leap: “It solved Erdős problems, therefore it’s basically a scientist now.”
Capability is not autonomy.
Aletheia DeepMind looks powerful because it’s a disciplined collaboration setup: humans choose the problems, humans set the standards, humans verify novelty and significance, and the system amplifies the tedious and error-prone parts of the loop.
That’s still a big deal. “Research collaborator” is an extremely high bar. It’s also the kind of progress that compounds, because once you have a reliable loop, every incremental model gain gets converted into real output more efficiently.
So here’s my practical closing take: don’t worship the score, steal the workflow.
If you’re building tools for reasoning, do this this week:
- Implement a generator verifier reviser loop in your stack.
- Make the verifier a different prompt, different tone, different job.
- Add a hard stop when it can’t justify a step.
- Log failures, then tune the harness, not just the model.
And if you want to read the primary sources instead of the internet telephone game, here are the PDFs you uploaded:
If you publish your own generate verify revise harness, or you find a benchmark edge case that breaks it, send it my way. That’s how this gets real.
1) What is Aletheia DeepMind?
Aletheia DeepMind is a math research agent built on Gemini Deep Think that iteratively generates, verifies, and revises proof attempts. It’s designed for research-style workflows where draft solutions get challenged, repaired, or rejected before you treat them as usable.
2) How is Aletheia different from a normal LLM?
A normal LLM typically gives you a single-pass answer, Aletheia runs an agent loop. It uses a generator for candidate proofs, a natural language verifier to find gaps, and a reviser to patch or restart, which makes it far more reliable for long proofs.
3) What is IMO-Bench and IMO-ProofBench Advanced?
IMO-Bench is a benchmark suite for Olympiad-level reasoning, and IMO-ProofBench Advanced focuses on proof writing under expert grading. It’s used to compare how well frontier reasoning systems construct valid arguments, not just final answers.
4) Did Aletheia solve any “unsolved” problems like Erdos-1051?
DeepMind’s case study reports an autonomous solution to Erdos-1051 as part of a wider sweep of problems labeled “Open” in Bloom’s Erdos problems database. The key detail is that “open” can mean genuinely unsolved, or simply obscure, so novelty is treated cautiously.
5) Can the public use Aletheia or Gemini Deep Think today?
Gemini Deep Think is available in the Gemini app depending on plan and region, and developers can use Gemini via API with published pricing. Aletheia itself is presented as a research agent workflow, not a single public model toggle you can enable.