

Introduction
You have seen this movie. A model tackles a hard problem, fails, tries again, fails differently, then repeats the same mistake with fresh confidence. You can sample more. You can crank temperature. You can run best of n sampling until the GPU fans sound like a small airport. And sometimes you still get nowhere, because the model is not learning from its own attempts.
TTT-Discover tries a more human move: when the model stumbles onto something useful, let it actually learn from it, mid-solve. Not “it learned a vibe,” but “it updated weights.” The paper frames the target as discovery problems, where you want one exceptional solution, not an average of decent ones.
Table of Contents
1. TTT-Discover In One Minute
Here is the whole idea in one breath. Take a hard, verifiable problem. Let a strong base model propose solutions. Score each attempt with a checker that returns a continuous reward, not just pass or fail. Do a tiny training step that nudges the policy toward what just worked. Repeat. At the end, return the best solution seen.
TTT-Discover Quick Table
Mobile-friendly summary of what TTT-Discover is, what it optimizes, and why it matters.
| What You Care About | Plain-English Answer | Why It Matters |
|---|---|---|
| What it is | A test time training LLM that updates weights while solving | It improves mid-run instead of only “trying again” |
| What it optimizes | One state-of-the-art solution, not average performance | Discovery is about the max, not the mean |
| Why it beats brute force | It remembers wins and leans into them | Sampling explores, learning explores and reinforces |
| What it needs | Continuous rewards plus a trustworthy verifier | You need signal you can climb |
| What it compares to | Best-of-25600 with the same budget | Fair match against Best-of-N sampling |
That last row is the important one. TTT-Discover is not claiming magic, it is claiming better allocation of the same compute.
2. What Problem It Is Actually Solving
Most ML training aims at an average. Average accuracy, average reward, average loss. Discovery flips that. You are not trying to be reliably good, you are trying to hit one new best.
The paper formalizes this cleanly: a discovery happens when a candidate state beats the best-known reward for that problem. That framing matters because standard reinforcement learning optimizes expected reward, and expected reward can be the wrong target when the only thing you care about is the tail.
They say it bluntly: in discovery, the policy can have low expected reward, as long as it reaches a new state of the art once. Read that again. TTT-Discover is allowed to be reckless, because it is not being deployed repeatedly.
This is why “reinforcement learning in ai” is the right mental category here, but also why naive RL feels misaligned. If your reward signal is nearly flat around the current best, you can spend a lot of compute improving the mean without ever pushing past the best.
3. Test-Time Training Vs Test-Time Scaling
People ask “what is test time training” and expect a single definition. There are at least two.
Classic test-time training adapts a model on unlabeled test data using self-supervision, often to handle distribution shifts. The new wave is more surgical: train at test time on the specific instance you are trying to solve, using a verifier to generate reward.
The paper points to systems like AlphaProof that generate targeted curricula at test time and then do RL on that generated data. TTT-Discover goes further: it trains directly on the test problem itself, and it does not pretend the learned behavior needs to generalize.
Now contrast that with test-time scaling, the frozen-model world. Best-of-N sampling, prompt evolution, tree search over prompts. You spend compute on more attempts, but every attempt forgets what the last one taught you. TTT-Discover makes a simple bet: spend compute on search plus learning.
4. TTT-Discover Vs Best-of-N Sampling Under The Same Budget

The fairest way to judge this method is compute matching. They do 50 training steps with 512 rollouts per step, so 25,600 total samples, then compare against Best-of-25600 using the same model and the same sampling budget.
Think of best of n sampling as pure exploration. You spray the space with attempts and hope one lands. TTT-Discover explores too, but it also reinforces the trail markers it just found. If a particular rewrite shaved off runtime, the next batch is not starting from the same policy that was clueless five minutes ago.
Reuse is the other half of the story. Instead of restarting from scratch every time, the system can start from promising partial solutions, effectively extending the horizon of a single attempt. That is how optimization happens in real life.
5. How TTT-Discover Works, No Math Required
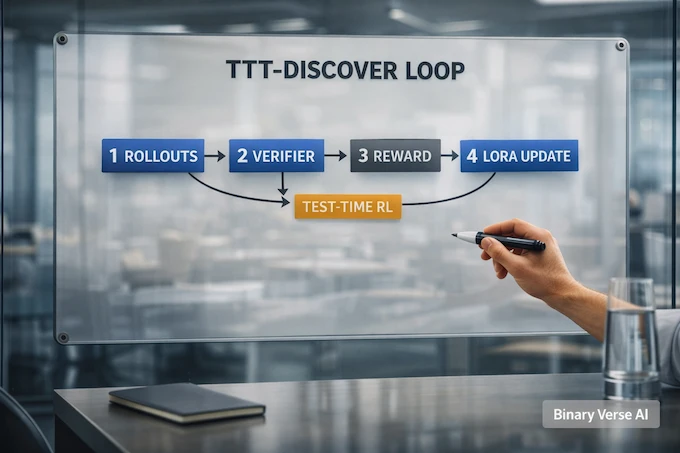
The loop is almost aggressively concrete:
- Pick an initial state, often a prior promising solution.
- Sample an action from the current policy, usually “think, then write code.”
- Parse or execute to get a new candidate solution.
- Score it with a verifier, producing a real-number reward.
- Add the trajectory to a buffer.
- Update the policy weights a tiny bit.
- Repeat, then return the best state seen.
This is where the “test time training paper” label earns its keep. The contribution is not inventing reinforcement learning. It is shaping RL for discovery, and pairing it with a reuse rule that compounds progress on one stubborn instance.
6. The Two Ingredients People Miss
6.1 Continuous Rewards
Binary rewards make search jumpy. Either the verifier says “pass” or “fail,” and the space between is invisible. Continuous rewards give you slope: inverse runtime for kernels, contest score for algorithms, a numeric bound for math constructions.
The method is built around that slope. It is also why the authors say the current form is limited to continuous rewards, and they call sparse or binary settings the key future direction.
6.2 Reuse Plus Guided Exploration
Discovery has no deployment phase, so you can be opportunistic about where you restart. Reuse turns “many short attempts” into “one long attempt with memory.”
They implement reuse with a PUCT-style rule that balances exploiting promising states with keeping diversity alive. In human terms, TTT-Discover keeps iterating on the good idea, but it still glances around for a better one.
7. What Gets Updated At Test Time
The scary version of test-time learning is “we fine-tune the whole model and ruin it.” TTT-Discover does something smaller.
They use LoRA with rank 32, run 50 training steps, and train each step on 512 rollouts. LoRA means the change lives in lightweight adapter weights, not a full rewrite of the base parameters.
They also add stability guardrails. The objective includes a KL penalty to limit drift, and they adapt their “sharpness” parameter per initial state by constraining KL.
TTT-Discover Test-Time Knobs
Key hyperparameters reported in the paper and how each knob changes behavior in practice.
| Test-Time Knob | Default In The Paper | What It Changes In Practice |
|---|---|---|
| Training steps | 50 | More steps, more compounding |
| Rollouts per step | 512 | More exploration per update |
| Update type | LoRA rank 32 | Lightweight specialization |
| Context window | 32,768 tokens | Long code can force truncation |
| KL regularization | 0.01 or 0.1 | Controls drift, improves stability |
| Reuse heuristic | PUCT, c=1.0 | Balances exploitation and diversity |
This is the practical core of TTT-Discover: constrained, instance-specific deep reinforcement learning that tries to get better without going off the rails.
8. Results Across Domains
The paper is unusually broad: math, GPU kernels, AtCoder heuristic contests, and single-cell denoising. They report results for every problem attempted, and say they set new state of the art in almost all of them, using only an open model.
A quick snapshot from the introduction table:
- Erdős minimum overlap: 0.380876 vs best human 0.380927 (lower is better).
- TriMul kernels: 2198 µs on A100 and 1161 µs on H100 vs best human 4531 µs and 1371 µs.
- AtCoder AHC39: 567,062 vs previous best AI 558,026.
- Denoising: 0.71 vs best human 0.64.
On the biology benchmark, they also compare directly against Best-of-25600 and OpenEvolve, and report the strongest numbers with TTT-Discover. They add a clear disclaimer that benchmark wins do not guarantee downstream biological validity, which is the right kind of caution.
If you want one technical reason to take the kernel results seriously, it is the verifier. They follow the competition’s correctness checks and timing procedures closely, then benchmark across iterations. That is the difference between “I made it faster” and “I made it faster in a way that survives reality.”
9. Reproducibility, The Honest Version
TTT-Discover is conceptually clean, but it is not “one command and you are done.”
They run experiments with an API called Tinker and estimate about $500 per run at default settings, with cost driven by token counts and sampling. They also summarize this as “a few hundred dollars per problem.”
The bigger barrier is not money, it is evaluation. You need a verifier that is fast, strict, and hard to game. If your reward is noisy, reinforcement learning will optimize noise with enthusiasm. If your verifier is slow, your run turns into a very expensive waiting room.
This is also why their best domains are the ones with crisp automated scoring: runtimes, contest scores, verifiable constructions. TTT-Discover is not a creativity amplifier. It is a metric amplifier.
10. Cost, Compute, And Practical Limits
TTT-Discover changes the shape of your compute. Best-of-N lets you stop the moment you get lucky. Test-time RL pays out when you compound, so you usually run the whole schedule.
The default recipe is heavy: 50 steps, 512 rollouts each, and a 32k context window that can vanish quickly inside long code and long traces. If you are trying to make this cheaper, the first knobs are predictable: speed up the verifier, shorten prompts, reduce rollouts, or reduce steps. Each knob trades off exploration, learning signal, or both.
And yes, infrastructure matters. In the kernel section they say they could submit to official leaderboards for some targets, but an infrastructure problem blocked submissions for others, so they worked with organizers to replicate environments locally. That is the glamorous underbelly of modern ML: half science, half DevOps.
11. The Hard Questions, Answered Directly
11.1 Is This A Real Shift Or Just Another Trick?
It is a real shift for problems that look like discovery. The key claim is simple: under the same sampling budget, learning at test time can beat search-only baselines like Best-of-25600.
The limits are also clear. The authors say the current form is for continuous rewards, and sparse or binary reward settings are the next frontier.
11.2 Does It Over-Specialize?
Yes, and that is the point. They even contrast this with “one example RL” work that aims to generalize, while TTT-Discover optimizes the test problem itself. If you need broad generalization, stop reading and go back to supervised fine-tuning.
11.3 What If The Checker Is Weak?
Then the method is weak. You are doing deep reinforcement learning against a reward model, so the reward model is the product. You can mitigate with strict validity checks and reject invalid states. But you do not get to escape the fundamental dependency: garbage reward in, garbage optimization out.
12. When To Use TTT-Discover
Treat this approach as a tool for turning test-time compute into test-time learning. It pays off when “better” is measurable and the prize for better is worth the bill.
Use it when:
- You have a fast, trustworthy verifier with continuous rewards.
- You want one exceptional solution, not average-case behavior.
- You can tolerate specialization and you actually want it.
Skip it when:
- Your goal is subjective or hard to score.
- Your evaluator is noisy, slow, or easy to game.
- You need robust performance across many tasks.
If this sounds like your world, do one concrete thing next: write down the metric you trust, then design the smallest verifier that enforces it. Once you have that, it becomes less like a research curiosity and more like a blueprint.
If you try it, share what broke. Share what surprised you. The best outcome here is not another leaderboard screenshot, it is a growing library of verifiers and environments where test-time learning is genuinely useful, and where it can earn its name again. You can explore the implementation on GitHub to get started with your own experiments using agentic AI tools and LLM orchestration frameworks.
1) What is test time training?
Test time training is a technique where a model updates its parameters during inference, using signals available at test time. Instead of staying frozen, the model adapts while solving, often using self-supervision or a verifier-based reward signal.
2) What is the training time vs test time?
Training time is when a model learns from a dataset before deployment. Test time (inference) is when it uses what it learned to answer new inputs. TTT-Discover blurs that line by doing small updates during test time, guided by evaluation feedback.
3) What is test time RL?
Test time RL is reinforcement learning performed during inference on the specific problem being solved. The model generates candidates, gets scored by a verifier, and then updates its policy so the next attempts are biased toward what just worked, within a compute budget.
4) What is best-of-n sampling in LLMs?
Best-of-n sampling means generating N candidate outputs from an LLM and picking the best one using a scorer or verifier. It improves results by exploration, but the model itself stays unchanged, so each attempt does not “learn” from previous tries.
5) What is test time scaling best-of-n?
Test time scaling with best-of-n is the practice of spending extra inference compute to generate more candidates, then selecting the best. It scales performance via search and selection, but it can plateau because the policy is frozen, unlike TTT-Discover-style test-time learning.