

MedQA Accuracy — Peer Comparison (Aug 12, 2025)
The top model records 96.3% on MedQA, narrowly ahead of 96.2% and 96.1% runners-up.
Others cluster in the 92–94% range, indicating a consistent but lower correctness on clinical questions.
For medical Q&A, this yields fewer errors per 100 items and steadier decision support.
| Model | Accuracy (%) |
|---|---|
| o3 | 96.1 |
| GPT-5 | 96.3 |
| GPT-5 Mini | 96.2 |
| Claude Opus 4.1 | 93.6 |
| Gemini 2.5 Pro Exp | 93.1 |
| Claude 4 Sonnet | 92.7 |
| Grok 4 | 92.5 |
Introduction
We keep asking the same question in clinics and labs. Can AI help us reason across messy, real patient data, not just spit back facts. The latest research on GPT-5 medical capabilities suggests a qualified yes. Across broad multimodal benchmarks and a focused neuro-oncology test on brain tumor MRI, GPT-5 shows real signal. Not magic. Not hype. Real progress in AI clinical reasoning.
“GPT5 is able to predict the outcomes of experiments that we haven’t even done.” — Dr. Daria Unutas
That is a bold claim. The good news, we can actually look at the evidence. Two new papers examine GPT-5 health performance from different angles, one across a wide sweep of multimodal medical reasoning tasks, the other inside a high-stakes niche, AI brain tumor MRI interpretation. Read them together and a picture emerges, GPT-5 is a strong generalist reasoner with encouraging, but still imperfect, specialty behavior. This is exactly the shape of technology you can productize carefully, with guardrails.
Table of Contents
1. The Context, Why GPT-5 Medical Matters Right Now

Clinical work is inherently multimodal. Doctors blend history, labs, vitals, imaging, and prior records, then make a call under uncertainty. Most older AI systems were narrow and unimodal. They detected a nodule or parsed a sentence, then stopped. GPT-5 changes the shape of the problem. It can ingest text and images, maintain a chain of thought, and stitch signals across modalities. If we care about safer triage, faster second reads, and better patient conversations, then strong multimodal medical reasoning matters.
The two studies in focus track that shift. The first paper evaluates general multimodal breadth. The second dives into one concrete specialty, differentiating tumor types on MRI. Together they test whether GPT-5 medical ability travels, from classroom-style questions to gritty specialist pattern recognition.
2. What The Studies Actually Tested
2.1 Broad Multimodal Reasoning
The capabilities paper assesses GPT-5 across MedQA, MMLU medical subsets, USMLE-style items, and two important multimodal datasets, MedXpertQA MM and VQA-RAD. It compares GPT-5 to GPT-4o and to pre-licensed human experts on specific tasks. The setup emphasizes zero-shot chain-of-thought, so we see reasoning, not just recall. In plain terms, can GPT-5 explain why an answer is right, and can it integrate visual context.
2.2 Brain Tumor MRI Reasoning
The neuro-oncology paper constructs a brain tumor VQA benchmark from BraTS cohorts covering glioblastoma, meningioma, and metastases. The models see triplanar MRI mosaics plus structured clinical cues, then answer targeted questions. This is not radiology board trivia. The task is practical, pick the likely tumor class from the images and context. The study reports macro-average accuracy across tumor types for GPT-5, GPT-5-mini, GPT-5-nano, and GPT-4o (arXiv).
3. Results At A Glance
Across the broad evaluation, GPT-5 medical performance clears a notable bar. It beats GPT-4o and, on MedXpertQA MM, even surpasses pre-licensed human experts on combined reasoning and understanding. That is a first for many readers. At the same time, in the MRI benchmark, accuracy is not yet clinic-ready. GPT-5-mini edges out GPT-5 on macro accuracy, and the absolute numbers remind us that specialty imaging remains hard.
Table 1. MedXpertQA, GPT-5 vs Human Experts
| Model | Text Reasoning | Text Understanding | Text Avg | MM Reasoning | MM Understanding | MM Avg |
|---|---|---|---|---|---|---|
| Expert, Pre-Licensed | 41.74 | 45.44 | 42.60 | 45.76 | 44.97 | 45.53 |
| GPT-4o-2024-11-20 | 30.63 | 29.54 | 30.37 | 40.73 | 48.19 | 42.80 |
| GPT-5 | 56.96 | 54.84 | 55.90 | 69.99 | 74.37 | 72.18 |
Takeaway. GPT-5 medical reasoning is particularly strong when text and images need to be integrated. The model clears expert averages on the multimodal track, a sign that the chain-of-thought training and visual grounding are doing real work (arXiv).
Table 2. Brain Tumor MRI Reasoning, Macro-Average Accuracy
| Model | Macro-Average Accuracy, % |
|---|---|
| GPT-5-mini | 44.19% |
| GPT-5 | 43.71% |
| GPT-4o | 41.49% |
| GPT-5-nano | 35.85% |
Takeaway. The scatter within cohorts matters. The study notes variation by tumor subtype and concludes that none of the models are yet fit for unsupervised clinical use. GPT-5 health progress is clear, deployment still needs supervision, calibration, and prospective validation.
4. How GPT-5 Medical Reasons Across Modalities
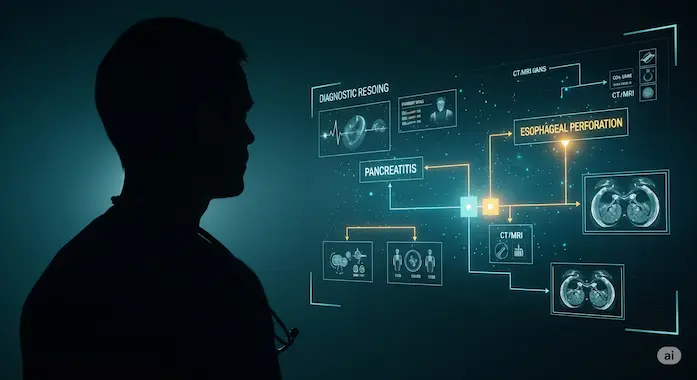
One MedXpertQA example is instructive. A middle-aged patient arrives after alcohol use with epigastric pain, elevated lipase, and CT signs suggesting pancreatitis. After treatment the patient develops suprasternal crepitus and blood-streaked emesis. GPT-5 shifts gears. It flags esophageal perforation, specifically Boerhaave syndrome, and recommends a water-soluble contrast esophagram, NPO, broad-spectrum antibiotics, and urgent surgical consult. It also explains why tempting alternatives are wrong. That is AI clinical reasoning, not lookup. The model tracks time-ordered events, weights new red flags higher than baseline, and maps symptoms to an action plan.
For teams evaluating GPT-5 vs human doctor behavior, this is the right lens. You want models that can change their mind when the story changes, that can pivot from pancreatitis to perforation, and that can state the consequences of missing the pivot.
5. Why The Numbers Look The Way They Do
Two trends explain the gap between tables.
First, GPT-5 medical reasoning benefits from diverse evidence and textual scaffolding. When the prompt includes history, vitals, labs, and an image, the model has more anchors, so its chain of thought lands on reliable landmarks. In pure image classification with tight phenotype boundaries, signal is scarcer and visual nuance dominates. That is where specialized radiology models still hold an edge.
Second, routing and scale matter. The studies evaluate GPT-5, GPT-5-mini, and GPT-5-nano. The smaller variant leads in MRI accuracy here, which hints at inductive bias and training data quirks. Do not assume bigger is always better. You may prefer GPT-5-mini for a specific pipeline if it exhibits steadier behavior on your distribution.
6. What Clinicians And Builders Should Do Next
If you lead an AI in healthcare team, treat GPT-5 medical capability as a powerful reasoning layer, then wrap it with domain-specific safety.
- Design for reading, not black boxes. Force the model to show its work. Persist intermediate rationales. Ask it to critique its own plan before final output.
- Tie outputs to actions. Do not stop at “likely diagnosis.” Capture next steps, tests, and watch-outs. This is where clinical value lives.
- Calibrate uncertainty. Some tasks need a calibrated risk score. Build temperature checks and abstention policies. Reward deferral when the model is unsure.
- Close the loop. Log outcomes. Feed back post-hoc truth to improve prompts, guardrails, and fine-tunes. GPT-5 performance improves when you close these loops.
7. Safety, Validation, And Trust
GPT-5 medical answers are often persuasive. That is a feature and a risk. You need procedures that keep persuasion aligned with reality.
- Prospective trials. Run shadow deployments with attending oversight. Measure sensitivity to distribution shift, especially across sites and scanners in AI brain tumor MRI.
- Ground truth discipline. Separate development labels from adjudicated clinical ground truth. Avoid training on the test. Keep a clean holdout.
- Human factors. Interface design matters. Surface uncertainty and contraindications clearly. Make it easy to disagree with the AI, not awkward.
8. GPT-5 Vs Human Doctor, Complement Or Competition
The right frame is complement. Doctors add context, values, and trust. GPT-5 adds tireless attention, memory across guidelines, and fast synthesis. On broad reasoning benchmarks, GPT-5 medical scores suggest that pairing the two will raise floor performance in day-to-day decisions. On specialist reads, the MRI results suggest a support role, not autonomy. Use the model to propose differentials, highlight edge patterns, and flag contradictions between report text and image evidence. Let the radiologist call the ball.
“It’s beyond collaborator. It’s almost like a mentor.” — Dr. Daria Unutas
Quotes like that capture the day-to-day reality for scientists and clinicians who have tried these tools. GPT-5 is not a replacement. It is a relentless second mind that critiques, suggests, and reminds. That is exactly how to frame it with patients and staff.
9. Practical Blueprint For Teams Shipping GPT-5 Medical Features
9.1 Data And Evaluation
- Assemble multimodal cases. Pair images with structured fields and free text. Your prompts should look like a real chart.
- Build unit tests for reasoning. Codify the steps you expect the model to take, then assert on intermediate answers.
- Track subgroup metrics. Slice by tumor subtype, scanner, age, and comorbidity. Watch variance, not just means.
9.2 Product And UX
- Explainable views. Show the text-image anchors the model used. Make edits copyable into notes.
- Guarded autonomy. Allow the model to auto-draft notes or orders only inside safe envelopes. Everything else requires a human click.
- Patient-facing clarity. When you use GPT-5 medical outputs in portals, keep language clear and supportive. Encourage patients to bring questions, not conclusions.
9.3 Engineering The Stack
• Routing with intent. For broad chart synthesis, call GPT-5 with full chain of thought. For a narrow image-first triage, consider GPT-5-mini alongside specialized classifiers.
• Caching and drift checks. Cache stable instructions and guidelines. Add drift monitors for both model behavior and input data distribution.
• Audit trails. Every recommendation needs a reproducible trace, prompt to output. You will thank yourself during post-event reviews.
10. Where This Goes Next
Expect three near-term improvements.
- Better calibration. Research on confidence estimation for large multimodal models is moving fast. Expect safer abstention.
- Retrieval-grounded reasoning. Blending GPT-5 medical reasoning with local guidelines and imaging atlases will tighten answers and reduce hallucinations.
- Few-shot domain tuning. Small, carefully curated packs of specialty cases will likely push MRI accuracy well past the current mid-40s. Not to autonomy, but to useful assistant levels.
11. The Bottom Line
GPT-5 medical capability is real. On integrated multimodal tasks, GPT-5 delivers strong AI clinical reasoning. On AI brain tumor MRI, it offers competitive assistance, with accuracy that still demands human supervision. If you are evaluating GPT-5 vs human doctor performance, the broad data supports augmentation. Use the model to expand attention, standardize quality, and raise the floor, while clinicians keep the ceiling high with judgment and empathy.
If you build in health, start now. Pick one workflow where multimodal medical reasoning helps, design for transparency, measure relentlessly, and keep a human in the loop. The teams that learn to pair human strengths with GPT-5 health capabilities will set the standard for the next decade of care.
Citations:
- Wang, S., Hu, M., Li, Q., Safari, M., & Yang, X. (2025). Capabilities of GPT-5 on Multimodal Medical Reasoning. arXiv. https://arxiv.org/abs/2508.08224v2
- Wang, S., Hu, M., Li, Q., Safari, M., & Yang, X. (2025). Performance of GPT-5 in Brain Tumor MRI Reasoning. arXiv. https://arxiv.org/abs/2508.10865
Written by Ezzah
Ezzah is a pharmaceutical research scholar and science writer exploring the frontiers of AI in medicine. She examines how GPT-5 is being tested in clinical reasoning, from integrating multimodal patient data to interpreting brain tumor MRI scans. With a background in pharmacology and a focus on translational medicine, she translates complex research into clear, practical insights for clinicians, researchers, and a global audience.
1) Is GPT-5 better than a doctor for diagnosis?
Short answer, not in real clinics. In controlled tests like MedXpertQA MM, GPT-5 topped pre-licensed human experts on reasoning and understanding, yet those are benchmarks, not bedside care. Use GPT-5 medical as a decision support layer, with final calls made by clinicians and within regulatory guardrails.
2) What can GPT-5 do in medicine and healthcare?
GPT-5 medical can synthesize notes, labs, and images, explain options in plain language, draft differentials and next steps, and spot contradictions across the chart. It shows stronger multimodal medical reasoning than prior models, which helps with triage, second reads, and patient education when supervised by clinicians.
3) How accurate is GPT-5 for medical diagnosis?
On research benchmarks, GPT-5 leads its peers and exceeds pre-licensed experts on MedXpertQA MM. In a brain tumor MRI benchmark, macro-average accuracy was about 43.7 percent for GPT-5, which is encouraging for support roles, not enough for autonomous use. Accuracy in the wild depends on case mix, data quality, and oversight.
4) Can GPT-5 analyze medical images like MRI scans?
Yes, in research settings. GPT-5 medical answers visual clinical questions and can reason over radiology inputs, including MRI mosaics, as shown in the brain tumor VQA study. Results are promising, though authors conclude performance is not clinic-ready without human review.
5) What is multimodal medical reasoning?
It is clinical reasoning that combines text, structured data, and medical images to reach a conclusion or plan. Reviews and recent papers define it as fusing multiple modalities to improve real-world decision making, which is where GPT-5 medical shows clear gains over prior models.
6) Will AI like GPT-5 replace doctors?
No. Leading guidance stresses human oversight, transparency, and accountability in health AI. GPT-5 medical can raise the floor on quality and efficiency, while clinicians provide judgment, empathy, and risk ownership. Think augmentation, not replacement.
7) How does GPT-5 help with medical research?
Teams use GPT-5 for hypothesis generation, rapid literature mapping, experiment planning, and code or data wrangling. Independent evaluations show stronger scientific and health performance than prior models, which supports its role as an assistant for study design and analysis, not as an unreviewed authority.
8) Is it safe to use GPT-5 for health questions?
Treat GPT-5 medical as information, not a diagnosis. Studies report chatbot health misinformation risks and real-world harm when advice is followed without medical supervision. Use it to prepare questions, not to self-treat, and confirm with a licensed clinician.