

Self-Distillation is one of those ideas that sounds suspicious on first contact. Train a model on its own raw outputs? No verifier, no teacher, no reward model, no reinforcement learning, no execution sandbox? That usually sounds like a fast route to elegant nonsense. Which is why this Apple AI research paper is so interesting. It takes the familiar fear behind llm model collapse and flips it on its head, at least in one very specific and very practical setting: code generation.
The core result is hard to ignore. Apple’s paper shows that Self-Distillation, done in a deliberately plain way, lifts Qwen3-30B-Instruct from 42.4 percent to 55.3 percent pass@1 on LiveCodeBench v6. The gains are bigger on harder problems, and they show up across Llama and Qwen models at 4B, 8B, and 30B scale. This is not a tiny ablation win hiding in an appendix. It is the sort of result that makes you sit up, reread the setup, and ask whether the field has been leaving useful capability on the table.
The teaser figure on page 1 basically tells the whole story. Sample from the model at one decoding setting, fine-tune on those outputs, then decode at another setting. That is the pipeline. No magic coat of varnish on top. Just a simple recipe with surprisingly sharp teeth.
The fast version looks like this:
| Question | Old Instinct | What Apple Shows |
|---|---|---|
| Can raw self-generated data help? | Usually risky, often associated with degradation | Yes, in code generation, if you sample and train the right way |
| Do you need a verifier or RL? | Usually yes for strong gains | No, standard supervised fine-tuning was enough here |
| Are gains cosmetic? | Maybe a few points from decoding tricks | No, the biggest model gained 12.9 points pass@1 |
| Does it only help easy tasks? | That would be the boring version | No, the largest gains show up on medium and hard problems |
| Does it kill diversity? | That would be the usual tradeoff | No, pass@5 often improves even more than pass@1 |
That summary is pulled from the paper’s headline figure and main benchmark table.
Table of Contents
1. The Big Claim Behind Self-Distillation
The usual story around synthetic data goes like this: if a model starts eating its own homework, quality drifts, quirks get amplified, and the tail eventually wags the dog. That concern is not silly. The paper itself opens from that premise, noting that human-written high-quality supervision is expensive, teacher-based distillation inherits the teacher’s ceiling, and RL pipelines remain operationally messy. Against that backdrop, the standard model collapse synthetic data argument feels perfectly reasonable.
What Apple adds is a sharper claim. The problem is not simply “synthetic data bad, human data good.” The real issue is what kind of synthetic data you make, how you sample it, and what the training objective does to the token distribution afterward. In other words, the paper is not declaring the death of collapse theory. It is showing that, under the right conditions, a model’s own outputs contain useful structure even when they are unverified. That is a subtler and much more interesting point.
There is also a broader industry implication here. Everyone wants to fine-tune without RL if they can get away with it. RL can work, but it is expensive, finicky, and easier to romanticize than to operate. A recipe that behaves like a post-training upgrade, while avoiding verifiers and reward loops, is automatically valuable. That is why this paper matters beyond the benchmark screenshot.
2. What Self-Distillation Actually Does
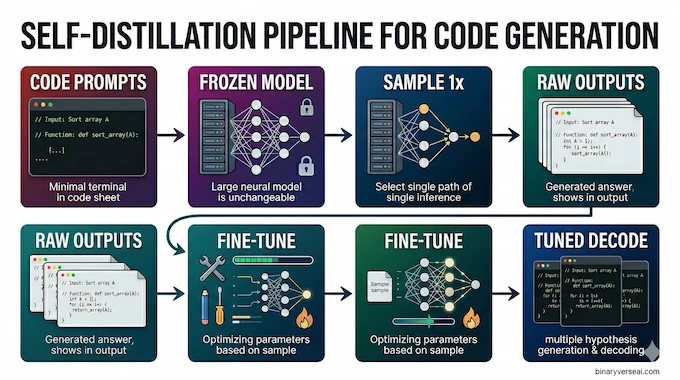
Here is self distillation explained without the ceremonial fog. Freeze the base model. Feed it a large set of coding prompts. Sample one answer per prompt with a chosen temperature and truncation setup. Keep the raw outputs, with only minimal filtering for empty junk. Then train the same model family on those outputs using ordinary cross-entropy, as if they were a supervised dataset. At inference time, use a separately tuned decoding setup. That is simple Self-Distillation in its pure form.
A few details make the result more credible. The paper used about 10,000 deduplicated competitive programming problems from the seed subset of rStar-Coder, and only one sampled solution per prompt was already enough to produce gains. There was no correctness filter. No unit tests. No hidden reward model pretending not to be a reward model. Just raw outputs and supervised fine-tuning. That is what the authors mean by simple self-distillation, and the simplicity is not marketing copy. It is the actual recipe.
There is also a practical sting in the tail. The reported training was not done on a hobbyist setup. The paper says fine-tuning used 8 B200 GPUs, with long sequence lengths and standard AdamW. So yes, the repo makes experimentation easier, and Apple has released a public implementation with evaluation scripts, but reproducing the headline numbers is not the same thing as casually poking a local laptop model over lunch. It is better to be honest about that now than to discover it at 2 a.m. with a smoking VRAM monitor.
3. Why Self-Distillation Does Not Collapse
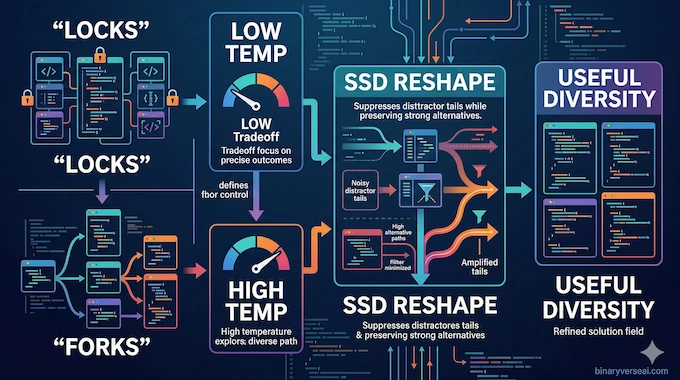
This is where the paper earns its keep. The authors argue that code is full of two very different token situations: locks and forks. A lock is a place where the right next token should be chosen with precision. Think syntax, variable references, or a structurally constrained continuation. A fork is a place where multiple continuations are genuinely plausible, like choosing between iteration, recursion, or a different data structure strategy. One setting wants strictness. The other wants exploration. A single global decoding temperature cannot satisfy both perfectly.
That tension is the paper’s central idea, the precision-exploration conflict. Lower temperature helps locks by suppressing distractor tokens, but it also starves forks by killing useful variation. Higher temperature helps forks by keeping alternatives alive, but it lets garbage creep back into locks. SSD helps because the model is not merely decoding differently after training. It is learning a different shape of probability distribution, one that suppresses distractor tails where precision matters and preserves useful diversity where exploration matters.
Here is the deliciously counterintuitive part. The paper even shows a pathological regime where sampled training outputs become bad enough that, by normal SFT standards, you would laugh them out of the room. Yet the student model still improves materially after training on them. That suggests the useful signal is not just hidden correctness. It is structural utility. The model learns from how the sampled distribution highlights and compresses options, not merely from whether the final program passes tests. That is a strange result, and strange results are often the ones worth remembering.
3.1. Why Self-Distillation Beats Decode-Only Tweaks
A fair objection is obvious: maybe you do not need training at all. Maybe the base model just needed better temperature tuning. The paper tests exactly that and finds the answer is no. For Qwen3-30B-Instruct, sweeping evaluation-time temperature on the base model only moved pass@1 from 41.3 to 43.5. SSD still beat the best decode-only setup by 11.8 points overall. On hard problems, the margin widened to 13.3 points at pass@1 and 19.4 at pass@5.
That matters because it means the method is doing more than finding a luckier knob position. Self-Distillation changes the model. It is not just a different way of sampling the same distribution. It is a way of teaching the model which parts of its own uncertainty are useful and which parts are mostly noise. That is a deeper intervention than “try temperature 0.8 instead of 0.7 and pray.”
4. The Self-Distillation Benchmarks Are Not Subtle
The benchmark story is unusually clean. On LiveCodeBench v6, every evaluated model improved. Llama-3.1-8B-Instruct gained 3.5 points at pass@1. Qwen3-4B-Instruct gained 7.5. Qwen3-4B-Thinking gained 3.3. Qwen3-30B-Thinking gained 2.1. The headliner, Qwen3-30B-Instruct, jumped from 42.4 to 55.3, which is a 12.9 point absolute increase and about a 30 percent relative gain.
Even better, the gains concentrate where you actually want them. For Qwen3-30B-Instruct, easy problems improved by 6.5 points, medium by 14.2, and hard by 15.3 at pass@1. At pass@5, the hard split jumped from 31.1 to 54.1. That is not the pattern of a model getting better at superficial formatting. That is the pattern of a model exploring harder solution space more effectively.
And no, it does not seem to buy those gains by collapsing diversity. Across the Qwen models, pass@5 often grows more than pass@1, which is exactly what you would hope to see if the method is preserving multiple useful solution branches rather than overfitting to one smug canonical answer.
A compact version of the most important numbers:
| Model | LCB v6 Pass@1 Base | LCB v6 Pass@1 +SSD | Gain | Hard Pass@5 Base | Hard Pass@5 +SSD |
|---|---|---|---|---|---|
| Llama-3.1-8B-Instruct | 12.7 | 16.2 | +3.5 | 0.8 | 3.3 |
| Qwen3-4B-Instruct | 34.0 | 41.5 | +7.5 | 16.5 | 34.1 |
| Qwen3-4B-Thinking | 54.5 | 57.8 | +3.3 | 45.8 | 53.1 |
| Qwen3-30B-Instruct | 42.4 | 55.3 | +12.9 | 31.1 | 54.1 |
| Qwen3-30B-Thinking | 66.1 | 68.2 | +2.1 | 59.7 | 65.8 |
| Model | LCB v6 Pass@1 Base | LCB v6 Pass@1 +SSD | Gain | Hard Pass@5 Base | Hard Pass@5 +SSD |
|---|---|---|---|---|---|
| Llama-3.1-8B-Instruct | 12.7 | 16.2 | +3.5 | 0.8 | 3.3 |
| Qwen3-4B-Instruct | 34.0 | 41.5 | +7.5 | 16.5 | 34.1 |
| Qwen3-4B-Thinking | 54.5 | 57.8 | +3.3 | 45.8 | 53.1 |
| Qwen3-30B-Instruct | 42.4 | 55.3 | +12.9 | 31.1 | 54.1 |
| Qwen3-30B-Thinking | 66.1 | 68.2 | +2.1 | 59.7 | 65.8 |
These values come directly from the main LiveCodeBench table in the paper.
5. Where Self-Distillation Travels, And Where It Bites Back
The obvious fear is catastrophic forgetting. Make a model better at competitive programming and maybe it becomes a socially awkward compiler with no general brain left. The paper’s transfer results are more reassuring than that, especially for the 30B models. Qwen3-30B-Instruct stays within about plus or minus 2 points across AIME, HumanEval, CruxEval, and MMLU. Its MMLU score barely moves, from 80.2 to 80.1. Qwen3-30B-Thinking behaves similarly, with MMLU moving from 78.7 to 78.4.
Smaller models are less graceful. Qwen3-4B-Instruct drops on AIME 2024 and HumanEval Shell, even while staying stable or slightly better on HumanEval Python and some CruxEval settings. Qwen3-4B-Thinking looks more mixed than disastrous. So the clean takeaway is not “SSD always generalizes beautifully.” It is “the larger models seem able to absorb this programming-only training without major collateral damage, while smaller models pay a more noticeable price.” That is a respectable result, but not a free lunch.
6. Can Self-Distillation Get Even Better With A Cheap Proxy?
One of the more interesting pieces in your source notes is not from the paper itself, but from the early community reaction around Apple’s repo. A commenter, urroxyz, suggested filtering SSD generations not by correctness but by usefulness, using a much smaller proxy model. Later, the same commenter reported a preliminary experiment where proxy-filtered data outperformed both raw SSD and correctness filtering on HumanEval+ by roughly 13 to 21 points in their setup.
That is anecdotal, not peer-reviewed, and the commenter explicitly says none of the fine-tuned variants beat the base model yet. Still, the direction is fascinating because it lines up with the paper’s deeper claim. Maybe the good training examples are not the ones that are strictly correct. Maybe they are the ones with the most useful internal structure, the ones that teach the student how to think its way through a space even when the final answer still misses the target. If that holds up, Self-Distillation could become less about harvesting correctness and more about shaping cognition. That is a much bigger idea.
7. What To Do With Self-Distillation Now
If you are a researcher, the immediate job is obvious. Replicate the result outside competitive programming, stress-test the transfer story, and figure out when distribution reshaping beats verification-heavy pipelines on cost and reliability. If you are building coding systems, the practical question is not “Should I replace everything with SSD tomorrow?” It is “Where in my post-training stack can this serve as a cheap capability multiplier?”
If you are an open-source tinkerer, Apple has already published the apple/ml-ssd repo with an evaluation path and a plain three-step overview: sample from a frozen model at non-unit temperature, fine-tune on unverified outputs, decode with a separately tuned temperature. That makes the idea inspectable, which matters. A result like this is much more useful when you can actually read the code instead of admiring a PDF from across the room.
The bigger lesson is philosophical. We have spent years assuming that a model mostly improves by being shown cleaner answers, stronger teachers, or better rewards. This paper hints at a different story. Sometimes the model already contains the raw ingredients for improvement. It just does not know how to redistribute its own attention over them. Self-Distillation works because it may teach the model to carve away the wrong uncertainty while keeping the right kind alive. That is less like giving the student an answer key and more like helping it develop taste.
So no, this does not prove the synthetic data skeptics were wrong. It does something more useful. It narrows the debate. It says collapse is not the only possible outcome, and that under the right decoding and training setup, a model’s own messy outputs can still be valuable training material. Self-Distillation is not the end of the story. It is the part where the story suddenly gets interesting. If you build, fine-tune, or study language models for a living, this is one paper worth reading closely, then testing yourself.
What is self-distillation in AI?
Self-distillation is a training method where an AI model learns from its own generated outputs instead of external labels or a stronger teacher. In Apple’s SSD setup, the model samples code solutions, fine-tunes on those raw outputs with standard supervised fine-tuning, and then decodes with tuned inference settings. On LiveCodeBench v6, that lifted Qwen3-30B-Instruct from 42.4% to 55.3% pass@1.
2. Does training an LLM on its own synthetic data cause model collapse?
It can, which is why model collapse became a serious concern in the first place. But Apple’s paper shows that collapse is not automatic. In this coding setup, carefully chosen temperature and truncation settings reshaped the model’s token distribution in a useful way, and the student improved even in a stress test built from very poor sampled outputs.
How is Simple Self-Distillation different from RLHF or GRPO?
Simple Self-Distillation skips the usual heavy machinery. Apple’s SSD does not use a verifier, reward model, teacher model, execution filter, or reinforcement learning. The recipe is just three steps: sample from the frozen model, fine-tune on raw unverified outputs with cross-entropy, then decode with separately tuned settings. That makes it far simpler operationally than RLHF-style or reward-driven pipelines.
Will self-distillation make an AI worse at general tasks?
Sometimes, but the answer depends on model size. In Apple’s results, the 30B models stayed broadly stable on out-of-domain benchmarks, and their MMLU scores stayed within 0.3 points. The smaller 4B models showed more uneven trade-offs, with some gains on coding-related transfer and some drops on other tasks. So SSD is not a free lunch, but it also is not automatic catastrophic forgetting.
Can I run simple self-distillation locally on my GPU?
You can experiment locally on smaller open-weight models or lighter fine-tuning setups, but reproducing Apple’s headline numbers is not a one-GPU weekend project. The paper says fine-tuning used Megatron-LM on 8 B200 GPUs, and synthetic data generation used vLLM with tensor-parallel generation across 8 GPUs. The public repo’s example evaluation command also uses tensor_parallel_size 4, which is a good clue about expected scale.