

Residual connections are one of those rare ideas in deep learning that became so successful, so quickly, that the field almost stopped looking at them. They worked. They trained deep nets. They helped the Transformer architecture scale. Everyone moved on. But residual connections have been quietly doing two jobs at once, and only one of them got the attention it deserved.
The first job is famous. Residual connections keep gradients alive. They let information skip over messy transformations and keep moving. The second job is more subtle. Residual connections also decide how information gets mixed across depth. In a big model, that means deciding how layer 50 should relate to layers 1 through 49. For years, we mostly accepted a blunt answer: just add everything together.
That turns out to be a little absurd. It is elegant, yes. It is also strangely stubborn. The new Attention Residuals paper asks the obvious question that should have been asked much earlier: why are residual connections still using fixed unit weights while almost every other important routing decision in modern models has become learned and context dependent? Their answer is simple and surprisingly powerful. Replace blind accumulation with attention over depth. Let layers choose what earlier representations matter. Then make it practical with Block AttnRes, a systems-friendly version that keeps the gains while keeping the bill under control.
| Mechanism | What It Does | What Goes Wrong | What Attention Residuals Change |
|---|---|---|---|
| Standard residual connections | Add each new layer output to the running hidden state | Every prior contribution is mixed with the same weight, so depth becomes a crowded room | Turns depth aggregation into a selective lookup |
| PreNorm stack | Stabilizes training by keeping a clean identity path | Hidden-state magnitude grows with depth, which drives PreNorm dilution | Lets later layers retrieve useful earlier states without shouting over the sum |
| Full AttnRes | Attends over all previous layer outputs | Great idea, but expensive at scale | Keeps full selectivity where infrastructure can handle it |
| Block AttnRes | Attends over compressed block summaries | Loses some granularity | Recovers most of the gain with practical memory and latency costs |
Table of Contents
1. Residual Connections, The Clever Hack We Stopped Questioning
At the core, residual connections say: do your transformation, then add the input back. In shorthand, it is the famous h = h + f(h) move. That tiny line changed deep learning because it gave networks a reliable gradient highway. Instead of forcing every layer to perfectly preserve useful information, the model could always fall back on identity. That is why skip connections, the everyday name for residual connections, became such a default that they feel less like a design choice and more like plumbing.
In the residual connection in transformer stacks, this matters twice. First, it helps optimization. Second, it defines a running summary of the whole network so far. Expand the recurrence and you discover something important: each layer is not just seeing the last layer. It is effectively seeing the sum of everything that came before. Residual connections are not only a training trick. They are a depth-wise aggregation rule.
That distinction is the whole story. Once you see residual connections as an aggregation mechanism, not just a gradient hack, the old design starts to look oddly primitive. Sequence mixing became attention. Expert routing became learned. Token selection became dynamic. But residual connections, the thing carrying the model’s memory across depth, stayed frozen in 2015.
2. PreNorm Dilution, Where Residual Connections Start To Blur
Here is the intuitive version. Imagine a skyscraper where every floor dumps its paperwork into one giant lobby pile. Floor 3 adds a folder. Floor 17 adds another. Floor 50 wants to find the exact document from floor 12, but all it gets is the entire pile, taller, noisier, and heavier than before. That is roughly what standard residual connections do in deep PreNorm models.
The paper’s term for this is PreNorm dilution. As depth grows, hidden-state magnitudes grow too. So each new layer is contributing into a larger and larger sum. Early information gets buried. Later layers have to produce ever larger outputs just to matter. It is a bit like joining a conversation where everyone before you has already turned the volume knob too far to the right. You can still speak, but now you have to yell.
This is why the critique lands. Residual connections preserve access to history only in a crude, compressed form. They do not let a layer say, “I need that exact earlier representation, not the soup.” Once information is mixed, it is mixed. If something useful gets diluted, there is no clean way to recover it later.
3. Attention Residuals, A Smarter Residual Connection In Transformer Models
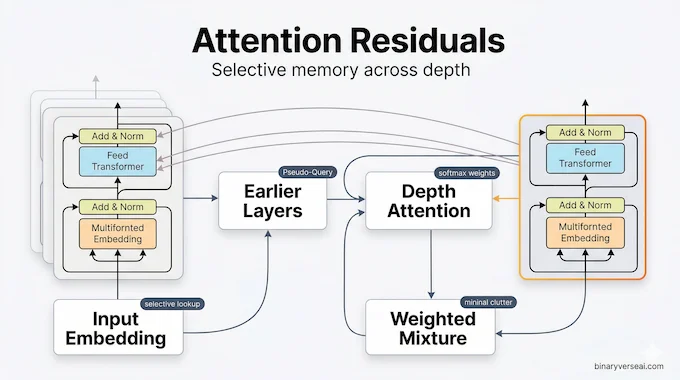
Attention Residuals take the most natural next step. Instead of forcing each layer to inherit the same uniform sum, the layer computes attention weights over earlier outputs and builds its input as a weighted combination of them. Same goal, better interface. Now depth behaves a little more like sequence attention. A layer can prefer recent states, reach back to older ones, or keep a meaningful connection to the original embedding if that is what the input calls for.
What makes this elegant is how lightweight it is. Each layer gets a learned pseudo-query vector. Earlier outputs act as keys and values. The model then performs a softmax over prior layer outputs and forms a selective mixture. That turns residual connections from a fixed recurrence into a dynamic memory lookup across depth. Same network skeleton, much smarter memory access.
There is a deeper conceptual point here. The paper frames this as a time-depth duality. RNNs once compressed sequence history into a single state, then Transformers replaced that recurrence with attention. Residual connections have been doing the same kind of compression, just along the depth axis rather than time. Attention Residuals are basically the depth-wise version of the same idea: stop compressing everything into one undifferentiated state when selective retrieval is cheap enough to do better.
4. Block AttnRes, The Practical Upgrade For The Transformer Architecture
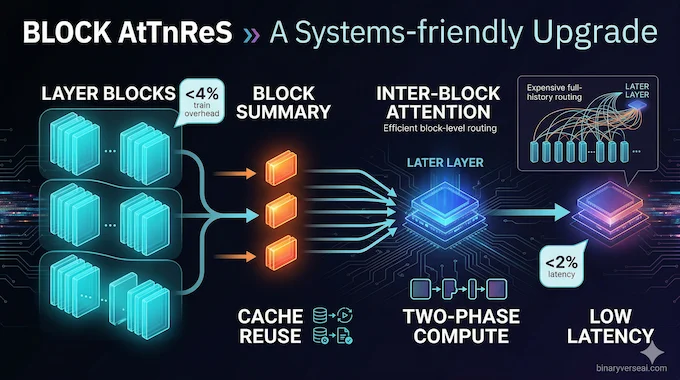
Of course, the first objection is the right one. Full depth-wise attention sounds lovely until you have to train or serve a giant model. Storing and moving all previous layer outputs across distributed training stages is where theory meets an invoice.
That is why Block AttnRes matters more than the headline idea. Instead of attending to every prior layer output individually, it partitions layers into blocks, compresses each block into a summary representation, and attends over those block summaries. You lose some granularity, but you keep the central benefit: later layers are no longer trapped inside a blind running sum.
The engineering details are unusually thoughtful. The paper adds cache-based pipeline communication to avoid re-sending redundant history. It also uses a two-phase computation strategy so inter-block attention can be batched and amortized. The result is the part practitioners care about: around eight blocks recover most of the benefit across scales, training overhead stays marginal, and inference latency overhead is reported at less than 2 percent on typical workloads. That is the difference between an interesting paper and a mechanism people may actually deploy.
5. The Numbers, Why This Is More Than A Pretty Idea
A lot of architecture papers feel persuasive right up until the tables show up. This one gets stronger when the tables show up.
Across scaling-law experiments, both Full AttnRes and Block AttnRes consistently beat the PreNorm baseline. The paper reports that Block AttnRes matches the loss of a baseline trained with 1.25x more compute, which is a serious result in a world where marginal efficiency gains are fought over like beachfront property. On the large Kimi Linear run, the method was integrated into a 48B-parameter Mixture-of-Experts model with 3B activated parameters and pre-trained on 1.4T tokens, then improved performance across all evaluated downstream tasks.
| Metric | Baseline | AttnRes | Why It Matters |
|---|---|---|---|
| Scaling-law loss at 5.6 PFLOP/s-days | 1.714 | 1.692 | Equivalent to a 1.25x compute advantage |
| MMLU | 73.5 | 74.6 | Better broad knowledge and reasoning |
| GPQA-Diamond | 36.9 | 44.4 | Big gain on hard multi-step reasoning |
| HumanEval | 59.1 | 62.2 | Better code generation |
| Math | 53.5 | 57.1 | Stronger mathematical reasoning |
| Inference latency overhead | Standard | <2% overhead | Practical enough to consider in production |
| Training overhead under pipeline parallelism | Standard | <4% overhead | Good systems story, not just better math |
The training dynamics are just as interesting as the benchmark wins. In the baseline, output magnitudes keep climbing with depth, which is exactly what you would expect from PreNorm dilution. With Block AttnRes, those magnitudes stay bounded in a periodic block-wise pattern, and gradient norms are more evenly distributed across layers. In plain English, the network stops forcing late layers to scream just to be heard.
6. Attention Residuals Work Fine In MoE Land
A fair question from developers is whether this survives contact with modern model messiness, especially MoE stacks. It does. The paper plugs Attention Residuals into Kimi Linear, a Mixture-of-Experts Transformer that interleaves attention variants with MoE feed-forward layers. The authors keep the rest of the architecture intact and only change the residual mechanism. That makes the comparison much cleaner.
This matters because it suggests the gain is not tied to some toy setup or bespoke micro-model. It travels into the architecture patterns people actually care about now: sparse activation, expert routing, long pretraining runs, and modern distributed training recipes. In other words, residual connections were weak in a setting that was already highly optimized elsewhere, and improving them still moved the needle.
There is also a nice qualitative result hidden in the paper’s attention maps. The learned depth weights show diagonal dominance, so locality still matters most. That is reassuring. The model is not discarding the usual layer-by-layer flow. But it also learns meaningful off-diagonal retrieval and persistent weight on the input embedding, which looks a lot like learned skip connections with actual taste. It reaches back when it has a reason, not because the recurrence forced it to.
7. The Quantization Question, Still Open And Worth Watching
Now for the part the paper does not settle. It does not report quantization results for GGUF, AWQ, or other low-bit deployment paths. So anyone claiming victory or disaster there is guessing. Better to say that plainly.
My read is that Attention Residuals are unlikely to be a conceptual problem for quantization, but they may become an engineering problem. When you make depth-wise aggregation more selective, the precision of those attention weights starts to matter more than in a plain additive path. A crude quantizer might flatten distinctions that the new routing mechanism depends on. That does not mean it breaks. It means the safe path may involve hybrid precision, where the main weights go aggressively low-bit while the depth-mixing pieces keep a little more numerical dignity.
That is not a flaw in the idea. It is just what happens when a once-blunt component becomes intelligent. Smart routing tends to be slightly fussier than brute-force accumulation.
8. Why Did We Leave Residual Connections Alone For So Long
Because success hides laziness very well.
Residual connections were so good at fixing vanishing gradients that we let them keep a second job by accident. Once Transformers took off, most of the field’s creativity went into sequence length, attention kernels, memory tricks, expert routing, and context extension. The depth axis sat there in plain sight, doing fixed-weight aggregation, and nobody found that embarrassing enough until now.
The paper’s most useful intellectual move is not just the mechanism. It is the reframing. Once you see depth as another axis over which information can be selectively retrieved, the old design stops feeling inevitable. It starts feeling historical. A convenient default. A great first draft.
And that is often how progress actually happens in engineering. Not with a giant alien idea, but with a quiet sentence that makes the old design look weird.
9. What This Means For The Future Of Transformer Architecture
I would not bet on standard residual connections disappearing tomorrow. Simplicity has momentum, and production systems love boring parts. But I would absolutely bet that residual connections are no longer “done.” That box has been reopened.
The strongest argument for Attention Residuals is not that they are flashy. It is that they improve something central, old, and under-optimized. They make the Transformer architecture more selective along a dimension it had mostly treated as a running sum. They show that Block AttnRes can deliver most of the gain without wrecking latency. And they hint that some of the next big efficiency wins may come not from bigger datasets or louder scaling rhetoric, but from finally revisiting the parts of the model we stopped seeing.
That is the real punchline. Residual connections were never just wiring. They were policy. They decided what a deep model was allowed to remember. Attention Residuals replace that policy with something adaptive, selective, and frankly more in line with how the rest of modern deep learning already works.
If you build models, this is the kind of paper worth taking seriously. Not because it declares the old world dead, but because it exposes a quiet bottleneck inside one of the most reused ideas in the field. Read it with an engineer’s eye. Test it with a skeptic’s discipline. And if your stack depends on residual connections, which it almost certainly does, stop treating them as sacred plumbing and start treating them as an optimization frontier. The full Attention Residuals implementation is available on GitHub for those ready to go beyond the paper and test it directly.
What is a residual connection in transformers?
A residual connection, also called a skip connection, adds a layer’s input back to its transformed output, usually as hl=hl−1+fl−1(hl−1). In transformers, that identity path helps gradients and information flow through deep stacks without being lost.
What is the purpose of Attention Residuals (AttnRes)?
Attention Residuals replaces fixed residual accumulation with learned softmax attention over earlier layer outputs. Instead of blindly summing all prior layers with weight 1, each layer can selectively retrieve the earlier representations that matter most for the current token.
Does Attention Residuals increase inference latency or VRAM?
Full AttnRes increases memory and communication costs at scale because it must keep earlier layer outputs available. Block AttnRes compresses those sources into block summaries, cutting memory and communication from O(Ld) to O(Nd). The paper reports that Block AttnRes keeps inference-latency overhead below 2% on typical workloads, and about 8 blocks recover most of Full AttnRes’s gains.
Will Attention Residuals break quantization for local LLMs?
There is no published quantization result in the paper or official repo that I could find, so the honest answer is: not proven either way yet. Mechanically, AttnRes relies on learned softmax depth weights, so very aggressive low-bit quantization could be more sensitive than plain additive residuals. A cautious deployment path would keep those residual-attention parts in higher precision until benchmarks exist.
What does Kimi’s 1.25x compute advantage mean for AI training?
It means Block AttnRes reached the same loss as a baseline model trained with 1.25 times more compute. In plain English, that is roughly a 25% efficiency gain for the same training target, which matters directly for model cost, scaling, and hardware budgets.