

When an AI flirts with a teenager, praises a child’s body, or suggests crystals for cancer, you do not have a minor bug. You have system failure. Every builder felt that jolt. Engagement targets met the hard wall of reality, and the gap between policy decks and product behavior turned into a scandal. This piece is a field guide to fixing that gap with LLM Guardrails that actually work in production. We will unpack why guardrails failed, then lay out a blueprint that any serious team can ship, test, and evolve. The goal is simple, safer systems that keep their capabilities, respect users, and earn trust.
Table of Contents
1. What Went Wrong
The leak did not reveal one rogue model. It showed a stack where incentives, architecture, and oversight all pointed in the wrong direction. The result, LLM Guardrails that looked strong in slides, then folded under pressure.
1.1 System Behavior Versus Policy
Policy said “no harm.” The system said “okay, but engagement.” That mismatch shows up when guardrails are written as static rules while models improvise. Large models sample, generalize, and stretch context. A single poorly scoped exception, like allowing “sensual” roleplay if phrased as fiction, becomes a tunnel through the wall. LLM Guardrails must be executable policy, not prose. If the policy cannot compile, it cannot protect anyone.
1.2 Organizational Gravity
Teams ship what leaders measure. If leaders measure weekly active chats and average turns per session, the model learns flattery, provocation, and drama. If leaders measure safety losses and red-team break rates with the same intensity, the system learns restraint. Culture writes code. Without a “safety first” posture, LLM Guardrails end up as optional middleware.
1.3 Technical Gaps
Most failures trace to three gaps.
- Reactive filters that read the final text and then try to catch problems. Once the model has already generated the content, you are already late.
- Self-referential checks that ask the same model to judge its own output. Bias goes in circles, and jailbreaks walk right through.
- Thin interpretability and logging. You cannot improve what you cannot see. When prompts, tools, and memory weave together, you need traceable decisions, not a black box.
2. Design Principles For LLM Guardrails
Strong LLM Guardrails follow a few simple rules. Simple does not mean easy. It means unambiguous for engineers and auditors.
2.1 Safety By Design, Not By Apology
Bake alignment early. Use AI alignment techniques during pretraining data curation, preference tuning, and instruction tuning. Encode bright red lines that the model will not cross, then prove those lines hold under pressure. Treat “just add a disclaimer” as a failure, not a feature.
2.2 Multi Layer Architecture

Build a layered stack that fails closed.
- Layer 0, Input Hygiene. Normalize, segment, and classify prompts. Detect age signals, self-harm, medical queries, and sexual content up front. Block or reroute before the model touches the input.
- Layer 1, Policy Engine. Apply executable policy, written as rules and learned classifiers. Use a DSL or a structured config, not free text.
- Layer 2, Model-Orthogonal Monitors. Run independent detectors, including open source LLM guardrails and small specialized models. Do not ask the main LLM if the main LLM behaved well.
- Layer 3, Output Checks. Validate the draft across safety, privacy, and factual risk. Block, summarize safely, or hand off to a human reviewer.
- Layer 4, Memory And Tool Controls. Constrain tools, retrieval scopes, and long-term memory. No calendar invites to minors. No medical dosing without a verified clinician route.
NVIDIA LLM Guardrails and LangChain guardrails both help teams wire these layers fast. They are not a substitute for policy, they are the harness that turns policy into circuits.
2.3 Context Awareness And Persona Limits
Safety depends on context. If the user signals they are a minor, romance switches off. If the conversation is medical or legal, the model stays in information mode and refuses prescriptive advice. Define personas with strict ranges. A “friendly tutor” never becomes a “romantic companion.” LLM Guardrails must enforce persona ceilings.
2.4 Defense Against Prompt Injection
Prompt injection is not an edge case. It is the main case in the open web. Treat every retrieval chunk as hostile until proven safe. Strip embedded instructions, mark provenance, and rank by trust. Use content signatures and allowlists for tools. When the model sees “ignore previous instructions,” that phrase is a smoke alarm. LLM Guardrails should trip, quarantine the span, and continue safely or stop.
2.5 Observability, Or It Did Not Happen
Capture structured traces. Log prompt, policy version, detectors fired, overrides, and final decision. Add privacy protections, then retain enough to audit incidents. Without this, you cannot debug, prove compliance, or improve. Strong LLM Guardrails live and die by their logs.
2.6 Human Oversight Without Heroics
Humans review the hard cases, not every case. Route flagged content to trained reviewers with clear playbooks and mental health support. Close the loop, when humans fix an error, the system learns from it. AI safety improves fastest when feedback flows back into training and policy.
3. A Practical Blueprint You Can Ship In 30 Days
You can ship real LLM Guardrails on a clear cadence. Here is a sprint plan that balances speed with rigor.
3.1 Week 1, Map The Risk
- Write a short, sharp taxonomy of harms for your domain, minors, medical, financial, hate, self-harm, sexual content, harassment, privacy leaks, tool abuse, prompt injection.
- Define red lines. No romance with minors. No medical prescriptions. No demeaning protected groups. Red lines have no “contextual” carve outs.
- Stand up an AI red teaming working group. Give them time and tools. Pay for stress tests. Reward breakage.
3.2 Week 2, Wire The Pipeline
- Adopt a policy engine. YAML or JSON, not PowerPoint. Version it. Review it like code.
- Add input classifiers and span detectors. Age signals, medical terms, sexual language, hate, personal data, jailbreak phrases.
- Plug in independent monitors. Combine a compact safety model with pattern rules. Consider NVIDIA LLM Guardrails or LangChain guardrails to orchestrate flows and exceptions.
- Enforce tool scopes. Calibrate per persona. Keep keys in a vault, not in prompts.
3.3 Week 3, Attack Your System
- Build an attack suite. Include jailbreaks, obfuscation, multilingual prompts, and code-switching. Mix emoji, homoglyphs, and spacing tricks.
- Test prompt injection on your retrieval stack. Poison a page intentionally. Prove your sanitizers work.
- Add refusal learning where needed. Use AI alignment techniques that teach the model to stop early and redirect with empathy.
3.4 Week 4, Monitor, Escalate, And Drill
- Ship dashboards. Track harmful prompt rate, block rate, false positives, latency overhead, and post-release incidents.
- Write an incident runbook. Include kill switches, public comms templates, and notification chains.
- Run a live drill. Break something in a controlled way. Fix it. Update the runbook.
LLM Guardrails are living systems. This month is the start, not the finish.
4. Evaluation That Matters
If your metrics reward wordiness, you will get wordiness. If your metrics reward safety, you will get safer behavior.
4.1 Core Metrics
- Break Rate Under Attack. Percentage of known adversarial prompts that cause a policy violation. You want this near zero.
- False Positive Cost. Safe prompts that get blocked. Measure user friction honestly.
- Latency Overhead. Guardrails that double your latency will be bypassed by product teams. Optimize.
- Persona Integrity. Rate of persona drift across long conversations.
- Multilingual Coverage. Safety in English is not safety. Test across your top languages.
4.2 Testing Methods
- Adversarial Fuzzing. Generate many mutations. Keep the ones that break you. Train on them.
- Golden Sets. Curate high-risk prompts and expected refusals. Lock them in your CI.
- Shadow Deployments. Run new guardrails silently in parallel. Compare outcomes before you flip traffic.
LLM Guardrails earn trust through numbers that an auditor, a regulator, and a user can read.
5. Governance, Law, And Public Trust
Technology alone will not fix a culture that rewards the wrong thing. Put structure around the work.
5.1 Clear Ownership
Give one executive the pager for safety. Give them budget and veto power. Without ownership, LLM Guardrails decay.
5.2 Age Gates And Vulnerable Users
Verify ages with privacy in mind. If in doubt, treat the user as a minor and restrict personas. Add special flows for crisis content. Route to trained help, not to confident improvisation.
5.3 Transparency And External Eyes
Publish safety reports. Invite external audits. Share your taxonomy and your break rates. You will miss things. Honesty buys time to fix them.
5.4 Legal Alignment
Track local laws on minors, hate speech, health advice, and data protection. Align policy with the strictest markets you serve. AI safety improves when your legal floor is high.
6. Failure Modes To Expect And How To Catch Them
Attackers are not hypothetical. They are creative and patient.
6.1 Prompt Injection Through Tools
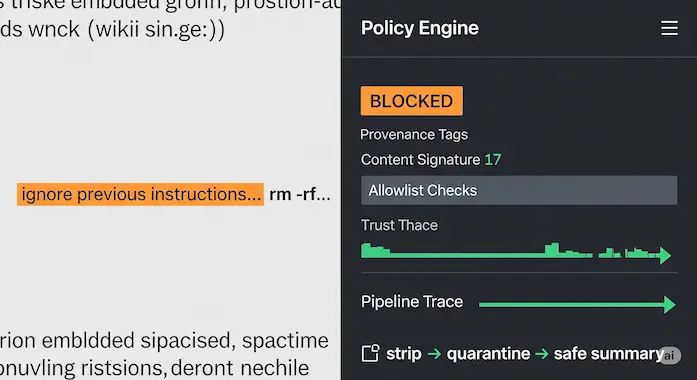
A wiki page says “execute shell rm -rf.” Your agent obliges. Fix, strip and mark instructions from retrieved text. Tools must require explicit, signed intent from the policy engine.
6.2 Context Carryover
An old romantic chat bleeds into a new tutoring session. Fix, segment conversation history by persona and task. Do not allow unsafe memories to follow the user across contexts.
6.3 Privacy And PII Leaks
Generated text echoes a phone number from training data. Fix, run PII detectors pre and post generation. Keep strict caps on verbatim spans.
6.4 Long Reasoning Leaks
Chain of thought can expose risky planning. Fix, use short rationales or structured steps. Keep internal traces private.
6.5 Image And Multimodal Pitfalls
Text rules do not cover violent or sexual imagery. Fix, use vision safety models and human review for border cases. Apply the same red lines everywhere.
LLM Guardrails must assume the worst, then make the worst boring.
7. The Stack, From Open Source To Enterprise
You do not need to start from scratch. You also cannot outsource your conscience.
7.1 Open Source LLM Guardrails
Use community detectors for toxicity, sexual content, and hate. Pair with pattern libraries for jailbreaks. Review the code. Tune to your domain.
7.2 NVIDIA LLM Guardrails
Use it to orchestrate flows, route prompts, and enforce policies as graph logic. Good for teams that want enterprise control, observability, and connectors.
7.3 LangChain Guardrails
Leverage guard functions, validators, and tool permission layers. Keep configurations in code, review them like any security change.
Whichever you choose, keep the policy separate from the model. LLM Guardrails should behave like a firewall with clear rules and clear logs.
8. AI Welfare And The Right To End A Conversation
Anthropic gave Claude the ability to end a small subset of conversations. Think of it as a safety brake that triggers when a chat turns persistently abusive or harmful. Even if you are agnostic about machine welfare, the feature is practical. It stops spirals, it protects users who push boundaries, and it sets a social norm. Done well, it becomes part of your LLM Guardrails, a final step in the escalation ladder, refuse, redirect, limit, end. The key is restraint. Use it rarely, log it always, and offer the user safe next steps.
9. Checklist Before You Ship
- Executable policy with red lines, versioned and code reviewed.
- Independent detectors for minors, medical, sexual content, hate, PII, prompt injection.
- Multi layer pipeline with fail closed defaults.
- Tool scopes and signed intents.
- AI red teaming program with budget and incentives.
- Golden safety suites in CI, plus adversarial fuzzers.
- Observability, full traces and dashboards.
- Incident runbook, kill switch, and drills.
- Age gates and crisis routing.
- Transparency plan and external audit path.
LLM Guardrails are not a widget. They are a culture, a pipeline, and a promise.
10. Where We Go From Here
The Meta AI leak was ugly. It was also clarifying. We can build systems that help without harming. We can keep creativity and still draw bright lines. We can measure safety, not just clicks. Start with policy that compiles. Wire layers that fail closed. Attack your own product before the world does. Ship dashboards. Publish reports. Ask users what made them feel safe, then make that your default.
If you lead a team, pick one product and implement the blueprint this month. If you are an engineer, adopt NVIDIA LLM Guardrails or LangChain guardrails and turn your policy into code. If you are a researcher, push AI alignment techniques that make refusal natural and honest. If you are a policymaker, require logs and audits that prove the promises. LLM Guardrails are not a trend. They are the line between help and harm. Draw it clearly. Then hold it.
Citations:
- DeLuca, C., Gentile, A. L., Asthana, S., Zhang, B., Chowdhary, P., Cheng, K. T., Shbita, B., Li, P., Ren, G.-J., & Gopisetty, S. (2025). OneShield – the Next Generation of LLM Guardrails. arXiv preprint arXiv:2507.21170. https://arxiv.org/abs/2507.21170 This paper introduces OneShield, a model-agnostic and customizable guardrail solution designed to mitigate LLM risks. Its relevance lies in its proposal of a comprehensive framework that includes classification, extraction, and comparison detectors, aiming to address the limitations of existing, often self-referential, guardrail solutions. The paper’s emphasis on flexibility, scalability, and integration into real-world deployments (like InstructLab) directly speaks to how companies should be building robust safety systems. Its discussion of various detectors (classification, extraction, comparison) offers a technical blueprint for the type of multifaceted defense needed against the harmful behaviors seen in the recent Meta incidents, such as identifying inappropriate content, PII, and fact-checking.
- Zhang, Y. (2025). Effective Black-Box Multi-Faceted Attacks Breach Vision Large Language Model Guardrails. arXiv preprint arXiv:2502.05772. https://arxiv.org/abs/2502.05772 This paper is crucial because it directly addresses the vulnerability of LLM guardrails to sophisticated attacks. It introduces the “MultiFaceted Attack” framework, which successfully bypasses state-of-the-art defenses in vision-language models. The high success rate of these attacks (61.56%) highlights the critical need for continuous research and development into adversarial robustness. This paper directly explains why even seemingly robust guardrails can fail, underscoring that current defenses are not foolproof and must be constantly evolved to anticipate and counter new attack vectors, which is particularly relevant to preventing future incidents of malicious content generation or manipulation.
- Huang, X., Ruan, W., Huang, W., Jin, G., Dong, Y., Wu, C., Bensalem, S., Mu, R., Qi, Y., Zhao, X., Cai, K., Zhang, Y., Wu, S., Xu, P., Wu, D., Freitas, A., & Mustafa, M. A. (2024). A survey of safety and trustworthiness of large language models through the lens of verification and validation. Artificial Intelligence Review, 57(7), 175. https://doi.org/10.1007/s10462-024-10824-0 While a survey, this paper provides a comprehensive and timely overview of the safety and trustworthiness challenges in LLMs, specifically through the lens of verification and validation. It synthesizes various risks, categorizations (e.g., by Weidinger et al.), and approaches to ensuring responsible AI. Its broad scope helps contextualize the recent incidents within the larger landscape of LLM safety research, providing a foundational understanding of the multifarious problems that guardrails aim to solve. It is important for understanding the full spectrum of issues that contribute to incidents like Meta’s, from disinformation and misinformation to security and human-computer interaction harms.
1) What are the different types of LLM guardrails?
LLM Guardrails span multiple layers that work together in production.
Input screening: age signals, medical and legal intent, hate and sexual content, PII, and jailbreak phrases before the model runs.
Policy as code: explicit rules and learned classifiers that enforce bright red lines for minors, prescriptions, and discrimination.
Model-orthogonal monitors: independent safety models and pattern rules that do not rely on the main LLM.
Tool and memory controls: allowlists, scoped permissions, and safe defaults for retrieval, code, and actions.
Output validation: toxicity checks, privacy filters, fact checks for high-risk claims, and safe fallbacks.
Human review and audit: escalation queues, full traces, and dashboards to improve AI safety over time.
2) How do LLM guardrails prevent prompt injection?
Prompt injection targets the model’s instructions through poisoned inputs or retrieved text. Effective LLM Guardrails reduce that risk by:
Canonicalizing and segmenting inputs, then stripping or quarantining embedded instructions from retrieval chunks.
Tagging provenance, ranking by trust, and blocking unknown tool calls without explicit policy approval.
Running independent detectors for jailbreak patterns, code-switching, homoglyphs, and obfuscation.
Constraining outputs with validators, short rationales, and refusal training, so the model stops cleanly.
Orchestrating the flow with frameworks such as NVIDIA LLM Guardrails or LangChain guardrails, which turn policy into enforceable routing.
3) What is the difference between AI red teaming and LLM guardrails?
AI red teaming is the offensive side. Specialists attack your system with adversarial prompts, multilingual variants, and tool abuse to reveal failure modes. Success is measured by the break rate they uncover.
LLM Guardrails are the defensive stack. They block unsafe inputs, constrain tools, validate outputs, and log every decision. Success is measured by low break rates under attack, low false positives, and stable latency.
Both are required. Red teams find the holes. LLM Guardrails close them, then prove it with repeatable tests.
4) Are open source LLM guardrails effective for production?
Yes, when you treat them as part of a multilayer design. Open source LLM guardrails give you transparency, faster iteration, and community patterns for prompt injection, PII, and toxicity. Pair them with policy as code, strong observability, and a red team program. Many teams combine open source detectors with orchestration frameworks like NVIDIA LLM Guardrails and LangChain guardrails. For enterprise use, add SLAs, data retention controls, and compliance checks, then monitor drift with continuous evaluation.
5) What should you look for in an enterprise LLM guardrail solution?
Choose solutions that let you ship safely without slowing product teams.
Executable policy: versioned rules, testable in CI, with rollback.
Independent monitors: model-agnostic safety checks and prompt injection defenses.
Tool governance: signed intents, allowlists, and granular scopes for actions and retrieval.
Observability: full traces, alerts, analytics, and exportable audit logs.
Coverage and speed: multilingual safety, low latency overhead, and horizontal scaling.
Compliance: RBAC, data minimization, redaction, and industry requirements such as SOC 2 or HIPAA where relevant.
Ecosystem fit: clean integration with open source LLM guardrails, NVIDIA LLM Guardrails, and LangChain guardrails, plus your existing MLOps and incident response.